Data integration
[2] It has become the focus of extensive theoretical work, and numerous open problems remain unsolved.
[4] Issues with combining heterogeneous data sources, often referred to as information silos, under a single query interface have existed for some time.
In the early 1980s, computer scientists began designing systems for interoperability of heterogeneous databases.
[6] By making thousands of population databases interoperable, IPUMS demonstrated the feasibility of large-scale data integration.
This problem frequently emerges when integrating several commercial query services like travel or classified advertisement web applications.
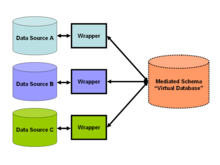
A trend began in 2009 favoring the loose coupling of data[8] and providing a unified query-interface to access real time data over a mediated schema (see Figure 2), which allows information to be retrieved directly from original databases.
This problem addresses not the structuring of the architecture of the integration, but how to resolve semantic conflicts between heterogeneous data sources.
For example, if two companies merge their databases, certain concepts and definitions in their respective schemas like "earnings" inevitably have different meanings.
A common strategy for the resolution of such problems involves the use of ontologies which explicitly define schema terms and thus help to resolve semantic conflicts.
On the other hand, the problem of combining research results from different bioinformatics repositories requires bench-marking of the similarities, computed from different data sources, on a single criterion such as positive predictive value.
This enables the data sources to be directly comparable and can be integrated even when the natures of experiments are distinct.
[14] Organizations are more frequently using data mining for collecting information and patterns from their databases, and this process helps them develop new business strategies to increase business performance and perform economic analyses more efficiently.
[15] Consider a web application where a user can query a variety of information about cities (such as crime statistics, weather, hotels, demographics, etc.).
But any single enterprise would find information of this breadth somewhat difficult and expensive to collect.
This means application-developers construct a virtual schema—the mediated schema—to best model the kinds of answers their users want.
Next, they design "wrappers" or adapters for each data source, such as the crime database and weather website.
These adapters simply transform the local query results (those returned by the respective websites or databases) into an easily processed form for the data integration solution (see figure 2).
This solution offers the convenience of adding new sources by simply constructing an adapter or an application software blade for them.
The virtual ETL solutions leverage virtual mediated schema to implement data harmonization; whereby the data are copied from the designated "master" source to the defined targets, field by field.
[18] Connections to particular databases systems such as Oracle or DB2 are provided by implementation-level technologies such as JDBC and are not studied at the theoretical level.
The burden of complexity falls on implementing mediator code instructing the data integration system exactly how to retrieve elements from the source databases.
As is illustrated in the next section, the burden of determining how to retrieve elements from the sources is placed on the query processor.
The designer would add corresponding elements for weather to the global schema only if none existed already.
[20] One can loosely think of a conjunctive query as a logical function applied to the relations of a database such as "
While the designer does the majority of the work beforehand, some GAV systems such as Tsimmis involve simplifying the mediator description process.
The integration system must execute a search over the space of possible queries in order to find the best rewrite.
[21] If the space of rewrites is relatively small, this does not pose a problem — even for integration systems with hundreds of sources.
Large-scale questions in science, such as real world evidence, global warming, invasive species spread, and resource depletion, are increasingly requiring the collection of disparate data sets for meta-analysis.
National Science Foundation initiatives such as Datanet are intended to make data integration easier for scientists by providing cyberinfrastructure and setting standards.
The OpenPHACTS project, funded through the European Union Innovative Medicines Initiative, built a drug discovery platform by linking datasets from providers such as European Bioinformatics Institute, Royal Society of Chemistry, UniProt, WikiPathways and DrugBank.