Database model
Most database software will offer the user some level of control in tuning the physical implementation, since the choices that are made have a significant effect on performance.
Columns of the table often have a type associated with them, defining them as character data, date or time information, integers, or floating point numbers.
They are characterized primarily by being navigational with strong connections between their logical and physical representations, and deficiencies in data independence.
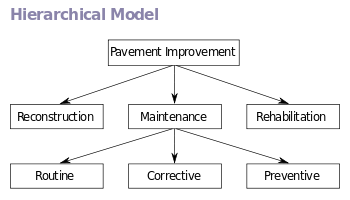
In a hierarchical model, data is organized into a tree-like structure, implying a single parent for each record.
This structure is very efficient to describe many relationships in the real world; recipes, table of contents, ordering of paragraphs/verses, any nested and sorted information.
Because of this, the hierarchical structure is inefficient for certain database operations when a full path (as opposed to upward link and sort field) is not also included for each record.
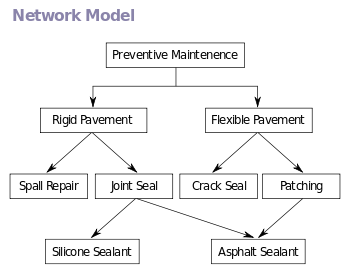
The network model organizes data using two fundamental concepts, called records and sets.
Although it is not an essential feature of the model, network databases generally implement the set relationships by means of pointers that directly address the location of a record on disk.
This gives excellent retrieval performance, at the expense of operations such as database loading and reorganization.
Popular DBMS products that utilized it were Cincom Systems' Total and Cullinet's IDMS.
IDMS gained a considerable customer base; in the 1980s, it adopted the relational model and SQL in addition to its original tools and languages.
This is also the logical structure of contemporary database indexes, which might only use the contents from a particular columns in the lookup table.
Document-oriented database Clusterpoint uses inverted indexing model to provide fast full-text search for XML or JSON data objects for example.
The relational model was introduced by E.F. Codd in 1970[2] as a way to make database management systems more independent of any particular application.
It is a mathematical model defined in terms of predicate logic and set theory, and implementations of it have been used by mainframe, midrange and microcomputer systems.
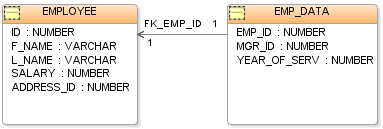
The basic data structure of the relational model is the table, where information about a particular entity (say, an employee) is represented in rows (also called tuples) and columns.
Keys are also critical in the creation of indexes, which facilitate fast retrieval of data from large tables.
In the dimensional model, a database schema consists of a single large table of facts that are described using dimensions and measures.
Dimensions tend to be discrete and are often hierarchical; for example, the location might include the building, state, and country.
In an OLAP query, dimensions are chosen and the facts are grouped and aggregated together to create a summary.
An alternative physical implementation, called a snowflake schema, normalizes multi-level hierarchies within a dimension into multiple tables.
Its high performance has made the dimensional model the most popular database structure for OLAP.
Paradoxically, this allows products that are historically pre-relational, such as PICK and MUMPS, to make a plausible claim to be post-relational.
This also results in fewer reads, less referential integrity issues, and a dramatic decrease in the hardware needed to support a given transaction volume.
However, object database ideas were picked up by the relational vendors and influenced extensions made to these products and indeed to the SQL language.