Disjoint-set data structure
This specialized type of forest performs union and find operations in near-constant amortized time.
For a sequence of m addition, union, or find operations on a disjoint-set forest with n nodes, the total time required is O(mα(n)), where α(n) is the extremely slow-growing inverse Ackermann function.
Disjoint-set data structures play a key role in Kruskal's algorithm for finding the minimum spanning tree of a graph.
The importance of minimum spanning trees means that disjoint-set data structures support a wide variety of algorithms.
In addition, these data structures find applications in symbolic computation and in compilers, especially for register allocation problems.
(inverse Ackermann function) upper bound on the algorithm's time complexity,.
In 1979, he showed that this was the lower bound for a certain class of algorithms, that include the Galler-Fischer structure.
[8] In 2007, Sylvain Conchon and Jean-Christophe Filliâtre developed a semi-persistent version of the disjoint-set forest data structure and formalized its correctness using the proof assistant Coq.
Variants of disjoint-set data structures with better performance on a restricted class of problems have also been considered.
Gabow and Tarjan showed that if the possible unions are restricted in certain ways, then a truly linear time algorithm is possible.
[10] Each node in a disjoint-set forest consists of a pointer and some auxiliary information, either a size or a rank (but not both).
Every array entry requires Θ(log n) bits of storage for the parent pointer.
If a root is represented by a node that points to itself, then adding an element can be described using the following pseudocode: This operation has linear time complexity.
As long as memory allocation is an amortized constant-time operation, as it is for a good dynamic array implementation, it does not change the asymptotic performance of the random-set forest.
The Find operation follows the chain of parent pointers from a specified query node x until it reaches a root element.
Performing a Find operation presents an important opportunity for improving the forest.
When a Find is executed, there is no faster way to reach the root than by following each parent pointer in succession.
However, the parent pointers visited during this search can be updated to point closer to the root.
This updating is an important part of the disjoint-set forest's amortized performance guarantee.
The constant memory implementation walks from the query node to the root twice, once to find the root and once to update pointers: Tarjan and Van Leeuwen also developed one-pass Find algorithms that retain the same worst-case complexity but are more efficient in practice.
The choice of which node becomes the parent has consequences for the complexity of future operations on the tree.
In both cases, the size of the new parent node is set to its new total number of descendants.
[11] Using union by rank, but without updating parent pointers during Find, gives a running time of
The inverse Ackermann function grows extraordinarily slowly, so this factor is 4 or less for any n that can actually be written in the physical universe.
[12][13][14][15] Lemma 1: As the find function follows the path along to the root, the rank of node it encounters is increasing.
We claim that as Find and Union operations are applied to the data set, this fact remains true over time.
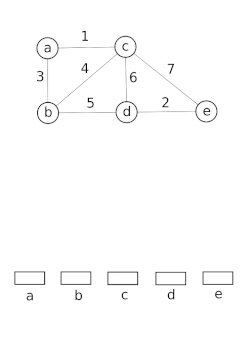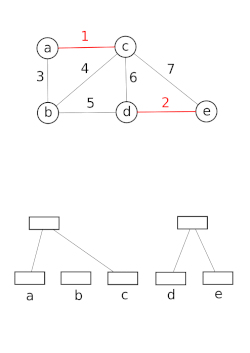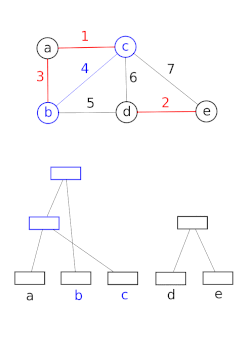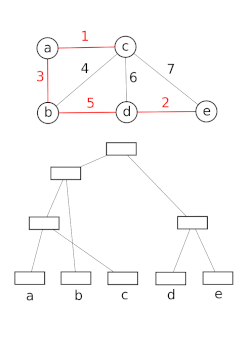
However, there exist modern implementations that allow for constant-time deletion and where the time-bound for Find depends on the current number of elements[18][19] Disjoint-set data structures model the partitioning of a set, for example to keep track of the connected components of an undirected graph.
This model can then be used to determine whether two vertices belong to the same component, or whether adding an edge between them would result in a cycle.
[20] This data structure is used by the Boost Graph Library to implement its Incremental Connected Components functionality.
It is also a key component in implementing Kruskal's algorithm to find the minimum spanning tree of a graph.

MakeSet
creates 8 singletons.

Union
, some sets are grouped together.