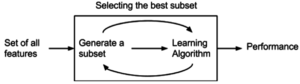
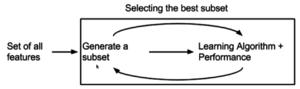
Feature selection
The simplest algorithm is to test each possible subset of features finding the one which minimizes the error rate.
This is an exhaustive search of the space, and is computationally intractable for all but the smallest of feature sets.
The choice of evaluation metric heavily influences the algorithm, and it is these evaluation metrics which distinguish between the three main categories of feature selection algorithms: wrappers, filters and embedded methods.
More robust methods have been explored, such as branch and bound and piecewise linear network.
Subset selection algorithms can be broken up into wrappers, filters, and embedded methods.
Exhaustive search is generally impractical, so at some implementor (or operator) defined stopping point, the subset of features with the highest score discovered up to that point is selected as the satisfactory feature subset.
The stopping criterion varies by algorithm; possible criteria include: a subset score exceeds a threshold, a program's maximum allowed run time has been surpassed, etc.
Search approaches include: Two popular filter metrics for classification problems are correlation and mutual information, although neither are true metrics or 'distance measures' in the mathematical sense, since they fail to obey the triangle inequality and thus do not compute any actual 'distance' – they should rather be regarded as 'scores'.
Other available filter metrics include: The choice of optimality criteria is difficult as there are multiple objectives in a feature selection task.
Many common criteria incorporate a measure of accuracy, penalised by the number of features selected.
Examples include Akaike information criterion (AIC) and Mallows's Cp, which have a penalty of 2 for each added feature.
AIC is based on information theory, and is effectively derived via the maximum entropy principle.
[30][31] Other criteria are Bayesian information criterion (BIC), which uses a penalty of
for each added feature, minimum description length (MDL) which asymptotically uses
, maximum dependency feature selection, and a variety of new criteria that are motivated by false discovery rate (FDR), which use something close to
A maximum entropy rate criterion may also be used to select the most relevant subset of features.
[32] Filter feature selection is a specific case of a more general paradigm called structure learning.
Feature selection finds the relevant feature set for a specific target variable whereas structure learning finds the relationships between all the variables, usually by expressing these relationships as a graph.
The above may then be written as an optimization problem: The mRMR algorithm is an approximation of the theoretically optimal maximum-dependency feature selection algorithm that maximizes the mutual information between the joint distribution of the selected features and the classification variable.
Overall the algorithm is more efficient (in terms of the amount of data required) than the theoretically optimal max-dependency selection, yet produces a feature set with little pairwise redundancy.
mRMR is an instance of a large class of filter methods which trade off between relevancy and redundancy in different ways.
on the diagonal of H. Another score derived for the mutual information is based on the conditional relevancy:[38] where
An advantage of SPECCMI is that it can be solved simply via finding the dominant eigenvector of Q, thus is very scalable.
A recent method called regularized tree[44] can be used for feature subset selection.
Regularized trees naturally handle numerical and categorical features, interactions and nonlinearities.
They are invariant to attribute scales (units) and insensitive to outliers, and thus, require little data preprocessing such as normalization.
Generally, a metaheuristic is a stochastic algorithm tending to reach a global optimum.
The other variables will be part of a classification or a regression model used to classify or to predict data.
[49] This is a survey of the application of feature selection metaheuristics lately used in the literature.
[46] Some learning algorithms perform feature selection as part of their overall operation.