Formal grammar
However, it can also sometimes be used as the basis for a "recognizer"—a function in computing that determines whether a given string belongs to the language or is grammatically incorrect.
One of the interesting results of automata theory is that it is not possible to design a recognizer for certain formal languages.
Most languages have the meanings of their utterances structured according to their syntax—a practice known as compositional semantics.
As a result, the first step to describing the meaning of an utterance in language is to break it down part by part and look at its analyzed form (known as its parse tree in computer science, and as its deep structure in generative grammar).
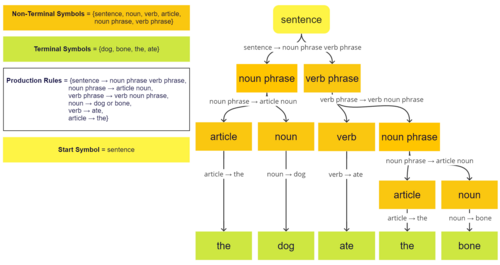
The language generated by the grammar is defined to be the set of all strings without any nonterminal symbols that can be generated from the string consisting of a single start symbol by (possibly repeated) application of its rules in whatever way possible.
If there are essentially different ways of generating the same single string, the grammar is said to be ambiguous.
In the following examples, the terminal symbols are a and b, and the start symbol is S. Suppose we have the following production rules: then we start with S, and can choose a rule to apply to it.
If we then choose rule 1 again, we replace S with aSb and obtain the string aaSbb.
If we now choose rule 2, we replace S with ba and obtain the string aababb, and are done.
in particular represents the number of times production rule 1 has been applied).
This grammar is context-free (only single nonterminals appear as left-hand sides) and unambiguous.
s. However, the language it generates is simply the set of all nonempty strings consisting of
For these examples, formal languages are specified using set-builder notation.
consists of the following production rules: This grammar defines the language
The difference between these types is that they have increasingly strict production rules and can therefore express fewer formal languages.
Although much less powerful than unrestricted grammars (Type 0), which can in fact express any language that can be accepted by a Turing machine, these two restricted types of grammars are most often used because parsers for them can be efficiently implemented.
[8] For example, all regular languages can be recognized by a finite-state machine, and for useful subsets of context-free grammars there are well-known algorithms to generate efficient LL parsers and LR parsers to recognize the corresponding languages those grammars generate.
This restriction is non-trivial; not all languages can be generated by context-free grammars.
the start symbol, and the following production rules: A context-free language can be recognized in
time (see Big O notation) by an algorithm such as Earley's recogniser.
That is, for every context-free language, a machine can be built that takes a string as input and determines in
[10] There exist various algorithms that target either this set of languages or some subset of it.
(Sometimes a broader definition is used: one can allow longer strings of terminals or single nonterminals without anything else, making languages easier to denote while still defining the same class of languages.)
the start symbol, and the following production rules: All languages generated by a regular grammar can be recognized in
Many extensions and variations on Chomsky's original hierarchy of formal grammars have been developed, both by linguists and by computer scientists, usually either in order to increase their expressive power or in order to make them easier to analyze or parse.
For example, a grammar for a context-free language is left-recursive if there exists a non-terminal symbol A that can be put through the production rules to produce a string with A as the leftmost symbol.
[15] An example of recursive grammar is a clause within a sentence separated by two commas.
Though there is a tremendous body of literature on parsing algorithms, most of these algorithms assume that the language to be parsed is initially described by means of a generative formal grammar, and that the goal is to transform this generative grammar into a working parser.
Strictly speaking, a generative grammar does not in any way correspond to the algorithm used to parse a language, and various algorithms have different restrictions on the form of production rules that are considered well-formed.
An alternative approach is to formalize the language in terms of an analytic grammar in the first place, which more directly corresponds to the structure and semantics of a parser for the language.