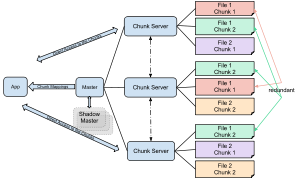
Google File System
It is also designed and optimized to run on Google's computing clusters, dense nodes which consist of cheap "commodity" computers, which means precautions must be taken against the high failure rate of individual nodes and the subsequent data loss.
[2] Files which are in high demand may have a higher replication factor, while files for which the application client uses strict storage optimizations may be replicated less than three times - in order to cope with quick garbage cleaning policies.
The file operations such as create, delete, open, close, read, write are supported.
Deciding from benchmarking results,[2] when used with relatively small number of servers (15), the file system achieves reading performance comparable to that of a single disk (80–100 MB/s), but has a reduced write performance (30 MB/s), and is relatively slow (5 MB/s) in appending data to existing files.
Aggregating multiple servers also allows big capacity, while it is somewhat reduced by storing data in three independent locations (to provide redundancy).