Google matrix
The PageRank of each page can then be generated iteratively from the Google matrix using the power method.
However, in order for the power method to converge, the matrix must be stochastic, irreducible and aperiodic.
In order to generate the Google matrix G, we must first generate an adjacency matrix A which represents the relations between pages or nodes.
Assuming there are N pages, we can fill out A by doing the following: Then the final Google matrix G can be expressed via S as: By the construction the sum of all non-negative elements inside each matrix column is equal to unity.
Usually S is a sparse matrix and for modern directed networks it has only about ten nonzero elements in a line or column, thus only about 10N multiplications are needed to multiply a vector by matrix G.[2][3] An example of the matrix
(1) within a simple network is given in the article CheiRank.
For the actual matrix, Google uses a damping factor
gives a surfer probability to jump randomly on any page.
belongs to the class of Perron-Frobenius operators of Markov chains.
[2] The examples of Google matrix structure are shown in Fig.1 for Wikipedia articles hyperlink network in 2009 at small scale and in Fig.2 for University of Cambridge network in 2006 at large scale.
which can be viewed as stationary probability distribution.
[2] These probabilities ordered by their decreasing values give the PageRank vector
used by Google search to rank webpages.
The number of nodes with a given PageRank value scales as
remain unchanged due to their orthogonality to the constant left vector at
gives a rapid convergence of a random initial vector to the PageRank approximately after 50 multiplications on
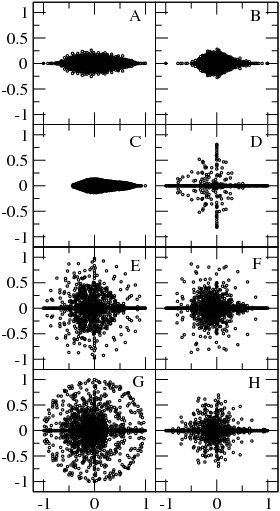
Examples of the eigenvalue spectrum of the Google matrix of various directed networks is shown in Fig.3 from [5] and Fig.4 from.
[8] The Google matrix can be also constructed for the Ulam networks generated by the Ulam method [8] for dynamical maps.
The spectral properties of such matrices are discussed in [9,10,11,12,13,15].
[5][9] In a number of cases the spectrum is described by the fractal Weyl law [10,12].
The Google matrix can be constructed also for other directed networks, e.g. for the procedure call network of the Linux Kernel software introduced in [15].
Numerical analysis shows that the eigenstates of matrix
Arnoldi iteration method allows to compute many eigenvalues and eigenvectors for matrices of rather large size [13].
matrix include the Google matrix of brain [17] and business process management [18], see also.
[1] Applications of Google matrix analysis to DNA sequences is described in [20].
Such a Google matrix approach allows also to analyze entanglement of cultures via ranking of multilingual Wikipedia articles abouts persons [21] The Google matrix with damping factor was described by Sergey Brin and Larry Page in 1998 [22], see also articles on PageRank history [23],[24].