Power iteration
The algorithm is also known as the Von Mises iteration.
[1] Power iteration is a very simple algorithm, but it may converge slowly.
The most time-consuming operation of the algorithm is the multiplication of matrix
by a vector, so it is effective for a very large sparse matrix with appropriate implementation.
In words, convergence is exponential with base being the spectral gap.
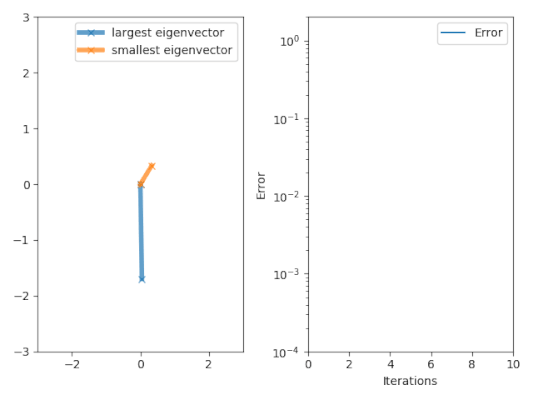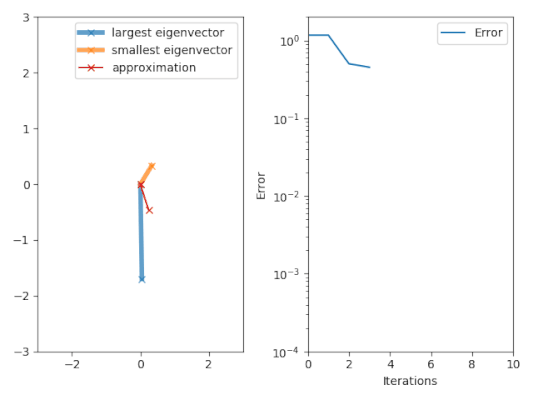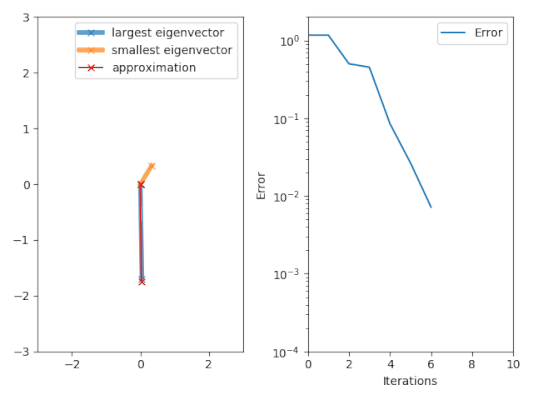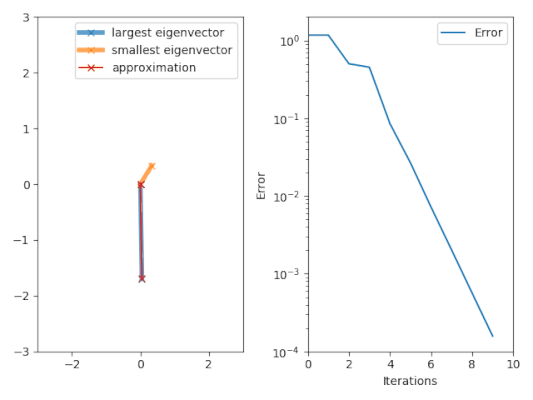
The power iteration algorithm starts with a vector
, which may be an approximation to the dominant eigenvector or a random vector.
The method is described by the recurrence relation So, at every iteration, the vector
has a nonzero component in the direction of an eigenvector associated with the dominant eigenvalue, then a subsequence
defined by converges to the dominant eigenvalue (with Rayleigh quotient).
[clarification needed] One may compute this with the following algorithm (shown in Python with NumPy): The vector
Ideally, one should use the Rayleigh quotient in order to get the associated eigenvalue.
This algorithm is used to calculate the Google PageRank.
The method can also be used to calculate the spectral radius (the eigenvalue with the largest magnitude, for a square matrix) by computing the Rayleigh quotient Let
be decomposed into its Jordan canonical form:
can be written as a linear combination of the columns of V: By assumption,
has a nonzero component in the direction of the dominant eigenvalue, so
The limit follows from the fact that the eigenvalue of
can be written in a form that emphasizes its relationship with
Note that the eigenvector corresponding to the dominant eigenvalue is only unique up to a scalar, so although the sequence
is nearly an eigenvector of A for large k. Alternatively, if A is diagonalizable, then the following proof yields the same result Let λ1, λ2, ..., λm be the m eigenvalues (counted with multiplicity) of A and let v1, v2, ..., vm be the corresponding eigenvectors.
Although the power iteration method approximates only one eigenvalue of a matrix, it remains useful for certain computational problems.
For instance, Google uses it to calculate the PageRank of documents in their search engine,[2] and Twitter uses it to show users recommendations of whom to follow.
[3] The power iteration method is especially suitable for sparse matrices, such as the web matrix, or as the matrix-free method that does not require storing the coefficient matrix
explicitly, but can instead access a function evaluating matrix-vector products
For non-symmetric matrices that are well-conditioned the power iteration method can outperform more complex Arnoldi iteration.
For symmetric matrices, the power iteration method is rarely used, since its convergence speed can be easily increased without sacrificing the small cost per iteration; see, e.g., Lanczos iteration and LOBPCG.
Some of the more advanced eigenvalue algorithms can be understood as variations of the power iteration.
Other algorithms look at the whole subspace generated by the vectors
Gram iteration[4] is a super-linear and deterministic method to compute the largest eigenpair.