Hopfield network
One of the key features of Hopfield networks is their ability to recover complete patterns from partial or noisy inputs, making them robust in the face of incomplete or corrupted data.
Sherrington and Kirkpatrick found that it is highly likely for the energy function of the SK model to have many local minima.
[20][21] A major advance in memory storage capacity was developed by Dimitry Krotov and Hopfield in 2016[22] through a change in network dynamics and energy function.
[27] A network with asymmetric weights may exhibit some periodic or chaotic behaviour; however, Hopfield found that this behavior is confined to relatively small parts of the phase space and does not impair the network's ability to act as a content-addressable associative memory system.
Updating one unit (node in the graph simulating the artificial neuron) in the Hopfield network is performed using the following rule:
where: Updates in the Hopfield network can be performed in two different ways: The weight between two units has a powerful impact upon the values of the neurons.
This generalization covered both asynchronous as well as synchronous dynamics and presented elementary proofs based on greedy algorithms for max-cut in graphs.
A subsequent paper[29] further investigated the behavior of any neuron in both discrete-time and continuous-time Hopfield networks when the corresponding energy function is minimized during an optimization process.
Bruck showed[28] that neuron j changes its state if and only if it further decreases the following biased pseudo-cut.
Note that this energy function belongs to a general class of models in physics under the name of Ising models; these in turn are a special case of Markov networks, since the associated probability measure, the Gibbs measure, has the Markov property.
However, while it is possible to convert hard optimization problems to Hopfield energy functions, it does not guarantee convergence to a solution (even in exponential time).
[35] The weight matrix of an attractor neural network[clarification needed] is said to follow the Storkey learning rule if it obeys:
[40] Ulterior models inspired by the Hopfield network were later devised to raise the storage limit and reduce the retrieval error rate, with some being capable of one-shot learning.
Rizzuto and Kahana (2001) were able to show that the neural network model can account for repetition on recall accuracy by incorporating a probabilistic-learning algorithm.
By adding contextual drift they were able to show the rapid forgetting that occurs in a Hopfield model during a cued-recall task.
In the original Hopfield model of associative memory,[18] the variables were binary, and the dynamics were described by a one-at-a-time update of the state of the neurons.
[25] The key theoretical idea behind dense associative memory networks is to use an energy function and an update rule that is more sharply peaked around the stored memories in the space of neuron's configurations compared to the classical model,[22] as demonstrated when the higher-order interactions and subsequent energy landscapes are explicitly modelled.
these equations reduce to the familiar energy function and the update rule for the classical binary Hopfield Network.
For Hopfield Networks, however, this is not the case - the dynamical trajectories always converge to a fixed point attractor state.
If the Hessian matrices of the Lagrangian functions are positive semi-definite, the energy function is guaranteed to decrease on the dynamical trajectory[25] This property makes it possible to prove that the system of dynamical equations describing temporal evolution of neurons' activities will eventually reach a fixed point attractor state.
In this case the steady state solution of the second equation in the system (1) can be used to express the currents of the hidden units through the outputs of the feature neurons.
The resulting effective update rules and the energies for various common choices of the Lagrangian functions are shown in Fig.2.
In the case of log-sum-exponential Lagrangian function the update rule (if applied once) for the states of the feature neurons is the attention mechanism[24] commonly used in many modern AI systems (see Ref.
Continuous Hopfield Networks for neurons with graded response are typically described[19] by the dynamical equations and the energy function where
In equation (9) it is a Legendre transform of the Lagrangian for the feature neurons, while in (6) the third term is an integral of the inverse activation function.
Biological neural networks have a large degree of heterogeneity in terms of different cell types.
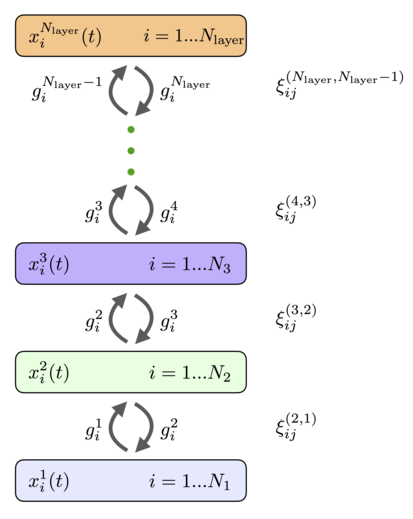
This section describes a mathematical model of a fully connected modern Hopfield network assuming the extreme degree of heterogeneity: every single neuron is different.
The temporal derivative of this energy function can be computed on the dynamical trajectories leading to (see [46] for details) The last inequality sign holds provided that the matrix
If, in addition to this, the energy function is bounded from below the non-linear dynamical equations are guaranteed to converge to a fixed point attractor state.
These top-down signals help neurons in lower layers to decide on their response to the presented stimuli.