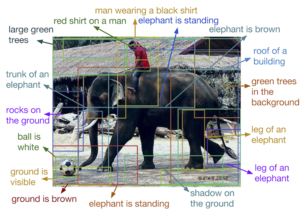
Automatic image annotation
Typically, image analysis in the form of extracted feature vectors and the training annotation words are used by machine learning techniques to attempt to automatically apply annotations to new images.
[1] The first methods learned the correlations between image features and training annotations.
Subsequently, techniques were developed using machine translation to to attempt to translate the textual vocabulary into the 'visual vocabulary,' represented by clustered regions known as blobs.
Subsequent work has included classification approaches, relevance models, and other related methods.
[2] At present, Content-Based Image Retrieval (CBIR) generally requires users to search by image concepts such as color and texture or by finding example queries.