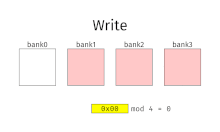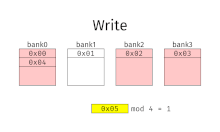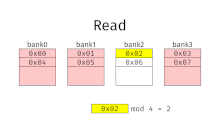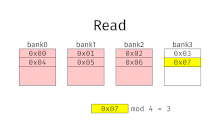
Interleaved memory
This results in significantly higher memory throughput as each bank has a minimum waiting time between reads and writes.
Row-buffer misses happen as access requests on different memory pages in the same bank are serviced.
The permutation-based interleaved memory method solved the problem with a trivial microarchitecture cost.
[2] This patent-free method can be found in many commercial microprocessors, such as AMD, Intel and NVIDIA, for embedded systems, laptops, desktops, and enterprise servers.
However, in reality memory reads are rarely random due to locality of reference, and optimizing for close together access gives far better performance in interleaved layouts.