Computational complexity theory
A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used.
More precisely, computational complexity theory tries to classify problems that can or cannot be solved with appropriately restricted resources.
The objective is to decide, with the aid of an algorithm, whether a given input string is a member of the formal language under consideration.
Deciding whether a given triple is a member of this set corresponds to solving the problem of multiplying two numbers.
Cobham's thesis argues that a problem can be solved with a feasible amount of resources if it admits a polynomial-time algorithm.
The ability to make probabilistic decisions often helps algorithms solve problems more efficiently.
For example, a non-deterministic Turing machine is a computational model that is allowed to branch out to check many different possibilities at once.
For a precise definition of what it means to solve a problem using a given amount of time and space, a computational model such as the deterministic Turing machine is used.
is the total number of state transitions, or steps, the machine makes before it halts and outputs the answer ("yes" or "no").
may be faster to solve than others, we define the following complexities: The order from cheap to costly is: Best, average (of discrete uniform distribution), amortized, worst.
If we assume that all possible permutations of the input list are equally likely, the average time taken for sorting is
Upper and lower bounds are usually stated using the big O notation, which hides constant factors and smaller terms.
Thus, a typical complexity class has a definition like the following: But bounding the computation time above by some concrete function
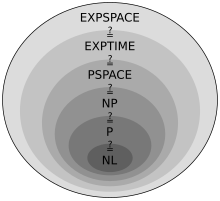
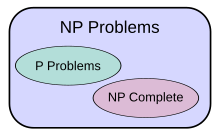
This forms the basis for the complexity class P, which is the set of decision problems solvable by a deterministic Turing machine within polynomial time.
Having deduced such proper set inclusions, we can proceed to make quantitative statements about how much more additional time or space is needed in order to increase the number of problems that can be solved.
The time and space hierarchy theorems form the basis for most separation results of complexity classes.
[3] The complexity class P is often seen as a mathematical abstraction modeling those computational tasks that admit an efficient algorithm.
The best algorithm for this problem, due to László Babai and Eugene Luks has run time
The best known algorithm for integer factorization is the general number field sieve, which takes time
The term infeasible (literally "cannot be done") is sometimes used interchangeably with intractable,[15] though this risks confusion with a feasible solution in mathematical optimization.
However, this identification is inexact: a polynomial-time solution with large degree or large leading coefficient grows quickly, and may be impractical for practical size problems; conversely, an exponential-time solution that grows slowly may be practical on realistic input, or a solution that takes a long time in the worst case may take a short time in most cases or the average case, and thus still be practical.
Similarly, algorithms can solve the NP-complete knapsack problem over a wide range of sizes in less than quadratic time and SAT solvers routinely handle large instances of the NP-complete Boolean satisfiability problem.
Even with a much faster computer, the program would only be useful for very small instances and in that sense the intractability of a problem is somewhat independent of technological progress.
[18] Control theory can be considered a form of computation and differential equations are used in the modelling of continuous-time and hybrid discrete-continuous-time systems.
[20] In addition, in 1965 Edmonds suggested to consider a "good" algorithm to be one with running time bounded by a polynomial of the input size.
[21] Earlier papers studying problems solvable by Turing machines with specific bounded resources include[20] John Myhill's definition of linear bounded automata (Myhill 1960), Raymond Smullyan's study of rudimentary sets (1961), as well as Hisao Yamada's paper[22] on real-time computations (1962).
Somewhat earlier, Boris Trakhtenbrot (1956), a pioneer in the field from the USSR, studied another specific complexity measure.
These ideas had occurred to me earlier in 1955 when I coined the term "signalizing function", which is nowadays commonly known as "complexity measure".
[24]In 1967, Manuel Blum formulated a set of axioms (now known as Blum axioms) specifying desirable properties of complexity measures on the set of computable functions and proved an important result, the so-called speed-up theorem.
The field began to flourish in 1971 when Stephen Cook and Leonid Levin proved the existence of practically relevant problems that are NP-complete.