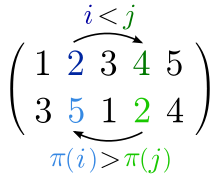Inversion (discrete mathematics)
In computer science and discrete mathematics, an inversion in a sequence is a pair of elements that are out of their natural order.
The inversion is indicated by an ordered pair containing either the places
A permutation's inversion set using place-based notation is the same as the inverse permutation's inversion set using element-based notation with the two components of each ordered pair exchanged.
Likewise, a permutation's inversion set using element-based notation is the same as the inverse permutation's inversion set using place-based notation with the two components of each ordered pair exchanged.
It is a common measure of sortedness (sometimes called presortedness) of a permutation[5] or sequence.
This last example shows that a set that is intuitively "nearly sorted" can still have a quadratic number of inversions.
The inversion number is the number of crossings in the arrow diagram of the permutation,[6] the permutation's Kendall tau distance from the identity permutation, and the sum of each of the inversion related vectors defined below.
Other measures of sortedness include the minimum number of elements that can be deleted from the sequence to yield a fully sorted sequence, the number and lengths of sorted "runs" within the sequence, the Spearman footrule (sum of distances of each element from its sorted position), and the smallest number of exchanges needed to sort the sequence.
[11] Standard comparison sorting algorithms can be adapted to compute the inversion number in time O(n log n).
They are often called inversion vector or Lehmer code.
This article uses the term inversion vector (
[13] The remaining two vectors are sometimes called left and right inversion vector, but to avoid confusion with the inversion vector this article calls them left inversion count (
Interpreted as a factorial number the left inversion count gives the permutations reverse colexicographic,[14] and the right inversion count gives the lexicographic index.
is the number of inversions whose smaller (right) component is
is the number of inversions whose bigger (right) component is
, often called Lehmer code:With the place-based definition
is the number of inversions whose smaller (left) component is
can be found with the help of a Rothe diagram, which is a permutation matrix with the 1s represented by dots, and an inversion (often represented by a cross) in every position that has a dot to the right and below it.
The permutation matrix of the inverse is the transpose, therefore
The following sortable table shows the 24 permutations of four elements (in the
column) with their place-based inversion sets (in the p-b column), inversion related vectors (in the
(The columns with smaller print and no heading are reflections of the columns next to them, and can be used to sort them in colexicographic order.)
are both related to the place-based inversion set.
are the sums of the descending diagonals of the shown triangle, and those of
(Pairs in descending diagonals have the right components 2, 3, 4 in common, while pairs in ascending diagonals have the left components 1, 2, 3 in common.)
The set of permutations on n items can be given the structure of a partial order, called the weak order of permutations, which forms a lattice.
The Hasse diagram of the inversion sets ordered by the subset relation forms the skeleton of a permutohedron.
If a permutation is assigned to each inversion set using the place-based definition, the resulting order of permutations is that of the permutohedron, where an edge corresponds to the swapping of two elements with consecutive values.
If a permutation were assigned to each inversion set using the element-based definition, the resulting order of permutations would be that of a Cayley graph, where an edge corresponds to the swapping of two elements on consecutive places.
This Cayley graph of the symmetric group is similar to its permutohedron, but with each permutation replaced by its inverse.