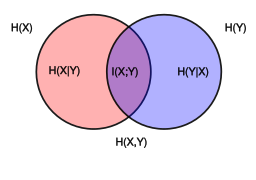
Mutual information
Not limited to real-valued random variables and linear dependence like the correlation coefficient, MI is more general and determines how different the joint distribution of the pair
The quantity was defined and analyzed by Claude Shannon in his landmark paper "A Mathematical Theory of Communication", although he did not call it "mutual information".
If the log base 10 is used, the unit of mutual information is the hartley, also known as the ban or the dit.
Mutual information is a measure of the inherent dependence expressed in the joint distribution of
Notice the analogy to the union, difference, and intersection of two sets: in this respect, all the formulas given above are apparent from the Venn diagram reported at the beginning of the article.
for the case of jointly discrete random variables: The proofs of the other identities above are similar.
The proof of the general case (not just discrete) is similar, with integrals replacing sums.
The first work to do this, which also showed how to do Bayesian estimation of many other information-theoretic properties besides mutual information, was.
See [8] for a recent paper based on a prior specifically tailored to estimation of mutual information per se.
[9] The Kullback-Leibler divergence formulation of the mutual information is predicated on that one is interested in comparing
carries over the matrix factorization is given by the Kullback-Leibler divergence The conventional definition of the mutual information is recovered in the extreme case that the process
The quantity satisfies the properties of a metric (triangle inequality, non-negativity, indiscernability and symmetry), where equality
[11] In a set-theoretic interpretation of information (see the figure for Conditional entropy), this is effectively the Jaccard distance between
This result has been used as a basic building block for proving other inequalities in information theory.
Some authors reverse the order of the terms on the right-hand side of the preceding equation, which changes the sign when the number of random variables is odd.
Note that The multivariate mutual information functions generalize the pairwise independence case that states that
[16] For arbitrary k variables, Tapia et al. applied multivariate mutual information to gene expression.
[13] The positivity corresponds to relations generalizing the pairwise correlations, nullity corresponds to a refined notion of independence, and negativity detects high dimensional "emergent" relations and clusterized datapoints [17]).
One high-dimensional generalization scheme which maximizes the mutual information between the joint distribution and other target variables is found to be useful in feature selection.
The term directed information was coined by James Massey and is defined as Note that if
Directed information has many applications in problems where causality plays an important role, such as capacity of channel with feedback.
However, in some applications it may be the case that certain objects or events are more significant than others, or that certain patterns of association are more semantically important than others.
This is because the mutual information is not sensitive at all to any inherent ordering in the variable values (Cronbach 1954, Coombs, Dawes & Tversky 1970, Lockhead 1970), and is therefore not sensitive at all to the form of the relational mapping between the associated variables.
If it is desired that the former relation—showing agreement on all variable values—be judged stronger than the later relation, then it is possible to use the following weighted mutual information (Guiasu 1977).
The AMI is defined in analogy to the adjusted Rand index of two different partitions of a set.
Using the ideas of Kolmogorov complexity, one can consider the mutual information of two sequences independent of any probability distribution: To establish that this quantity is symmetric up to a logarithmic factor (
are limited to be in a discrete number of states, observation data is summarized in a contingency table, with row variable
Mutual information is one of the measures of association or correlation between the row and column variables.
In fact, with the same log base, mutual information will be equal to the G-test log-likelihood statistic divided by
In many applications, one wants to maximize mutual information (thus increasing dependencies), which is often equivalent to minimizing conditional entropy.