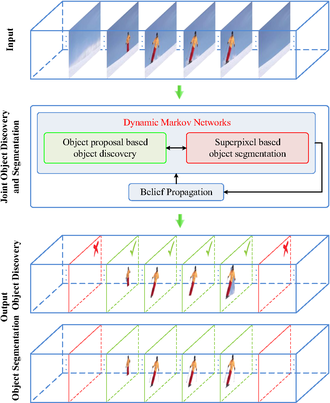
A joint object discover and co-segmentation method based on coupled dynamic Markov networks has been proposed recently,[1] which claims significant improvements in robustness against irrelevant/noisy video frames.
With such hypergraph extension, multiple modalities of correspondences, including low-level appearance, saliency, coherent motion and high level features such as object regions, could be seamlessly incorporated in the hyperedge computation.
In addition, as a core advantage over co-occurrence based approach, hypergraph implicitly retains more complex correspondences among its vertices, with the hyperedge weights conveniently computed by eigenvalue decomposition of Laplacian matrices.
Subsequently, the segment-tube detector refines per-frame spatial segmentation with graph cut by focusing on relevant frames identified by the temporal action localization step.
Upon practical convergence, the final spatio-temporal action localization results are obtained in the format of a sequence of per-frame segmentation masks (bottom row in the flowchart) with precise starting/ending frames.
Example video frames and their object co-segmentation annotations (ground truth) in the Noisy-ViDiSeg
[
1
]
dataset. Object segments are depicted by the red edge.
The inference process of the two coupled dynamic Markov networks to obtain the joint video object discovery and segmentation
[
1
]
A joint object discover and co-segmentation framework based on coupled dynamic Markov Networks
[
1
]
.
Overview of the coarse-to-fine temporal action localization in.
[
7
]
(a) Coarse localization. Given an untrimmed video, we first generate saliency-aware video clips via variable-length sliding windows. The proposal network decides whether a video clip contains any actions (so the clip is added to the candidate set) or pure background (so the clip is directly discarded). The subsequent classification network predicts the specific action class for each candidate clip and outputs the classification scores and action labels. (b) Fine localization. With the classification scores and action labels from prior coarse localization, further prediction of the video category is carried out and its starting and ending frames are obtained.
Flowchart of the spatio-temporal action localization detector segment-tube.
[
7
]
As the input, an untrimmed video contains multiple frames of actions (
e.g.
, all actions in a pair figure skating video), with only a portion of these frames belonging to a relevant category (
e.g.
, the DeathSpirals). There are usually irrelevant preceding and subsequent actions (background). The Segment-tube detector alternates the optimization of temporal localization and spatial segmentation iteratively. The final output is a sequence of per-frame segmentation masks with precise starting/ending frames denoted with the red chunk at the bottom, while the background are marked with green chunks at the bottom.