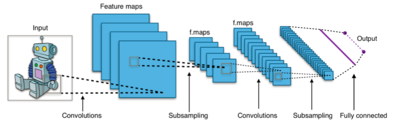
Convolutional neural network
[16] Convolutional networks were inspired by biological processes[17][18][19][20] in that the connectivity pattern between neurons resembles the organization of the animal visual cortex.
For example, atrous or dilated convolution[28][29] expands the receptive field size without increasing the number of parameters by interleaving visible and blind regions.
Their paper replaced multiplication with convolution in time, inherently providing shift invariance, motivated by and connecting more directly to the signal-processing concept of a filter, and demonstrated it on a speech recognition task.
[46] Since these TDNNs operated on spectrograms, the resulting phoneme recognition system was invariant to both time and frequency shifts, as with images processed by a neocognitron.
Wei Zhang et al. also applied the same CNN without the last fully connected layer for medical image object segmentation (1991)[50] and breast cancer detection in mammograms (1994).
In 1990 Yamaguchi et al. introduced the concept of max pooling, a fixed filtering operation that calculates and propagates the maximum value of a given region.
LeNet-5, a pioneering 7-level convolutional network by LeCun et al. in 1995,[52] classifies hand-written numbers on checks (British English: cheques) digitized in 32x32 pixel images.
The ability to process higher-resolution images requires larger and more layers of convolutional neural networks, so this technique is constrained by the availability of computing resources.
The model architecture was modified by removing the last fully connected layer and applied for medical image segmentation (1991)[50] and automatic detection of breast cancer in mammograms (1994).
[67][42][27] Subsequently, AlexNet, a similar GPU-based CNN by Alex Krizhevsky et al. won the ImageNet Large Scale Visual Recognition Challenge 2012.
A 1000×1000-pixel image with RGB color channels has 3 million weights per fully-connected neuron, which is too high to feasibly process efficiently at scale.
For example, in CIFAR-10, images are only of size 32×32×3 (32 wide, 32 high, 3 color channels), so a single fully connected neuron in the first hidden layer of a regular neural network would have 32*32*3 = 3,072 weights.
These models mitigate the challenges posed by the MLP architecture by exploiting the strong spatially local correlation present in natural images.
The layer's parameters consist of a set of learnable filters (or kernels), which have a small receptive field, but extend through the full depth of the input volume.
[73][nb 1] Stacking the activation maps for all filters along the depth dimension forms the full output volume of the convolution layer.
Pooling provides downsampling because it reduces the spatial dimensions (height and width) of the input feature maps while retaining the most important information.
A very common form of max pooling is a layer with filters of size 2×2, applied with a stride of 2, which subsamples every depth slice in the input by 2 along both width and height, discarding 75% of the activations:
In 2011, Xavier Glorot, Antoine Bordes and Yoshua Bengio found that ReLU enables better training of deeper networks,[84] compared to widely used activation functions prior to 2011.
[72] However, layers with a stride greater than one ignore the Nyquist-Shannon sampling theorem and might lead to aliasing of the input signal[72] While, in principle, CNNs are capable of implementing anti-aliasing filters, it has been observed that this does not happen in practice [86] and yield models that are not equivariant to translations.
[99] An earlier common way to deal with this problem is to train the network on transformed data in different orientations, scales, lighting, etc.
The alternative is to use a hierarchy of coordinate frames and use a group of neurons to represent a conjunction of the shape of the feature and its pose relative to the retina.
[20] CNNs were used to assess video quality in an objective way after manual training; the resulting system had a very low root mean square error.
The winner GoogLeNet[106] (the foundation of DeepDream) increased the mean average precision of object detection to 0.439329, and reduced classification error to 0.06656, the best result to date.
For example, they are not good at classifying objects into fine-grained categories such as the particular breed of dog or species of bird, whereas convolutional neural networks handle this.
[citation needed] In 2015, a many-layered CNN demonstrated the ability to spot faces from a wide range of angles, including upside down, even when partially occluded, with competitive performance.
[111][112][113] Long short-term memory (LSTM) recurrent units are typically incorporated after the CNN to account for inter-frame or inter-clip dependencies.
[114][115] Unsupervised learning schemes for training spatio-temporal features have been introduced, based on Convolutional Gated Restricted Boltzmann Machines[116] and Independent Subspace Analysis.
[136] Later it was announced that a large 12-layer convolutional neural network had correctly predicted the professional move in 55% of positions, equalling the accuracy of a 6 dan human player.
[147] So curvature-based measures are used in conjunction with geometric neural networks (GNNs), e.g. for period classification of those clay tablets being among the oldest documents of human history.
In contrast to previous models, image-like outputs at the highest resolution were generated, e.g., for semantic segmentation, image reconstruction, and object localization tasks.
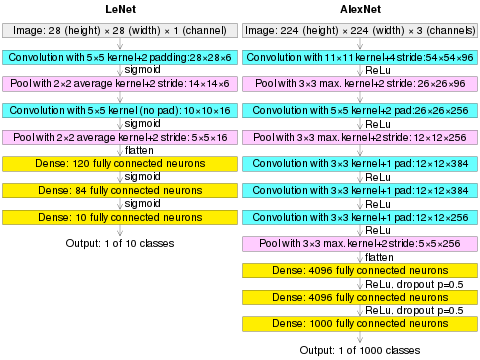
(AlexNet image size should be 227×227×3, instead of 224×224×3, so the math will come out right. The original paper said different numbers, but Andrej Karpathy, the head of computer vision at Tesla, said it should be 227×227×3 (he said Alex did not describe why he put 224×224×3). The next convolution should be 11×11 with stride 4: 55×55×96 (instead of 54×54×96). It would be calculated, for example, as: [(input width 227 - kernel width 11) / stride 4] + 1 = [(227 - 11) / 4] + 1 = 55. Since the kernel output is the same length as width, its area is 55×55.)