Rete algorithm
The algorithm was developed to efficiently apply many rules or patterns to many objects, or facts, in a knowledge base.
Charles Forgy has reportedly stated that he adopted the term 'Rete' because of its use in anatomy to describe a network of blood vessels and nerve fibers.
In most cases, the speed increase over naïve implementations is several orders of magnitude (because Rete performance is theoretically independent of the number of rules in the system).
In very large expert systems, however, the original Rete algorithm tends to run into memory and server consumption problems.
Rete networks act as a type of relational query processor, performing projections, selections and joins conditionally on arbitrary numbers of data tuples.
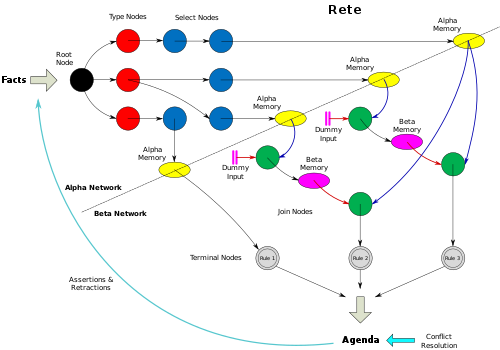
The "left" (alpha) side of the node graph forms a discrimination network responsible for selecting individual WMEs based on simple conditional tests that match WME attributes against constant values.
An alpha memory holds WM and performs "right" activations on the beta node each time it stores a new WME.
When a join node is left-activated it traverses a single newly stored WME list in the beta memory, retrieving specific attribute values of given WMEs.
During any one match-resolve-act cycle, the engine will find all possible matches for the facts currently asserted to working memory.
However, the sequence of production instance firings may be interrupted at any stage by performing changes to the working memory.
Rule actions can contain instructions to assert or retract WMEs from the working memory of the engine.
Each time any single production instance performs one or more such changes, the engine immediately enters a new match-resolve-act cycle.
As part of the new match-resolve-act cycle, the engine performs conflict resolution on the agenda and then executes the current first instance.
For this reason, most engines support explicit "halt" verbs that can be invoked from production action lists.
Some of the optimisations offered by Rete networks are only useful in scenarios where the engine performs multiple match-resolve-act cycles.
Universal quantification involves testing that an entire set of WMEs in working memory meets a given condition.
A variant of existential quantification referred to as negation is widely, though not universally, supported, and is described in seminal documents.
A good indexing strategy is a major factor in deciding the overall performance of a production system, especially when executing rule sets that result in highly combinatorial pattern matching (i.e., intensive use of beta join nodes), or, for some engines, when executing rules sets that perform a significant number of WME retractions during multiple match-resolve-act cycles.
The resulting Rete network contains sets of terminal nodes which, together, represent single productions.
For a more detailed and complete description of the Rete algorithm, see chapter 2 of Production Matching for Large Learning Systems by Robert Doorenbos (see link below).
In addition, the approach only applies to conditional patterns that perform equality tests against constant values.
However, in order to implement non-equality tests, the Rete may contain additional 1-input node networks through which WMEs are passed before being placed in a memory.
Each beta node performs its work and, as a result, may create new tokens to hold a list of WMEs representing a partial match.
Although not defined by the Rete algorithm, some engines provide extended functionality to support greater control of truth maintenance.
For example, an expert system might justify a conclusion that an animal is an elephant by reporting that it is large, grey, has big ears, a trunk and tusks.
Other approaches to performing rule evaluation, such as the use of decision trees, or the implementation of sequential engines, may be more appropriate for simple scenarios, and should be considered as possible alternatives.
Performance of Rete is also largely a matter of implementation choices (independent of the network topology), one of which (the use of hash tables) leads to major improvements.
To mention only a frequent bias and an unfair type of comparison: 1) the use of toy problems such as the Manners and Waltz examples; such examples are useful to estimate specific properties of the implementation, but they may not reflect real performance on complex applications; 2) the use of an old implementation; for instance, the references in the following two sections (Rete II and Rete-NT) compare some commercial products to totally outdated versions of CLIPS and they claim that the commercial products may be orders of magnitude faster than CLIPS; this is forgetting that CLIPS 6.30 (with the introduction of hash tables as in Rete II) is orders of magnitude faster than the version used for the comparisons (CLIPS 6.04).
Rete II gives about a 100 to 1 order of magnitude performance improvement in more complex problems as shown by KnowledgeBased Systems Corporation[9] benchmarks.
[12] This algorithm is now licensed to Sparkling Logic, the company that Forgy joined as investor and strategic advisor,[13][14] as the inference engine of the SMARTS product.