Richardson–Lucy deconvolution
The Richardson–Lucy algorithm, also known as Lucy–Richardson deconvolution, is an iterative procedure for recovering an underlying image that has been blurred by a known point spread function.
It was named after William Richardson and Leon B. Lucy, who described it independently.
[1][2] When an image is produced using an optical system and detected using photographic film or a charge-coupled device, for example, it is inevitably blurred, with an ideal point source not appearing as a point but being spread out into what is known as the point spread function.
Extended sources can be decomposed into the sum of many individual point sources, thus the observed image can be represented in terms of a transition matrix p operating on an underlying image: where
is the intensity of the underlying image at pixel
In most good optical systems (or in general, linear systems that are described as shift invariant) the transfer function p can be expressed simply in terms of the spatial offset between the source pixel j and the observation pixel i: where
is called a point spread function.
This has been written for one spatial dimension, but most imaging systems are two dimensional, with the source, detected image, and point spread function all having two indices.
So a two dimensional detected image is a convolution of the underlying image with a two dimensional point spread function
, the following iterative procedure is employed in which the estimate of
[3] Writing this more generally for two (or more) dimensions in terms of convolution with a point spread function P: where the division and multiplication are element wise,
is the mirrored point spread function, or the inverse Fourier transform of the Hermitian transpose of the optical transfer function.
In problems where the point spread function
is not known a priori, a modification of the Richardson–Lucy algorithm has been proposed, in order to accomplish blind deconvolution.
[4] In the context of fluorescence microscopy, the probability of measuring a set of number of photons (or digitalization counts proportional to detected light)
since in the context of maximum likelihood estimation the aim is to locate the maximum of the likelihood function without concern for its absolute value.
is a constant, it will not give any additional information regarding the position of the maximum, so consider where
can be written as: Tip: it is easy to see this by writing a matrix
For example in a typical case an element of the ground truth
Now as a seemingly arbitrary but key step, let where
operates as a matrix but the division and the product (implicit after
can be calculated because since it is assumed that - The initial guess
is known (and is typically set to be the experimental data) - The measurement function
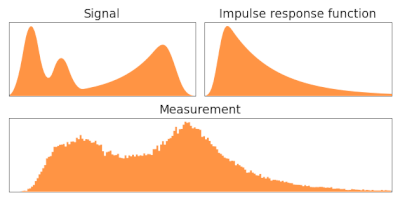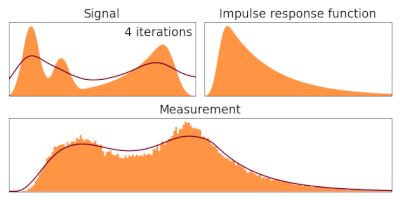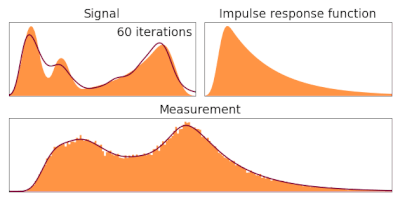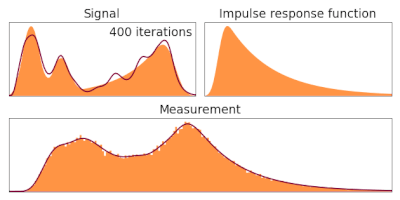
Therefore, equation (5) applied successively, provides an algorithm to estimate our ground truth
It has not been demonstrated in this derivation that it converges and no dependence on the initial choice is shown.
Note that equation (2) provides a way of following the direction that increases the likelihood but the choice of the log-derivative is arbitrary.
On the other hand equation (4) introduces a way of weighting the movement from the previous step in the iteration.
Note that if this term was not present in (5) then the algorithm would output a movement in the estimation even if
It's worth noting that the only strategy used here is to maximize the likelihood at all cost, so artifacts on the image can be introduced.
It is worth noting that no prior knowledge on the shape of the ground truth