Interpreter (computing)
In the 1960s, the introduction of time-sharing systems allowed multiple users to access a computer simultaneously, and editing interpreters became essential for managing and modifying code in real-time.
One of the earliest examples of an editing interpreter is the EDT (Editor and Debugger for the TECO) system, which was developed in the late 1960s for the PDP-1 computer.
EDT allowed users to edit and debug programs using a combination of commands and macros, paving the way for modern text editors and interactive development environments.
This is basically the same machine specific code but augmented with a symbol table with names and tags to make executable blocks (or modules) identifiable and relocatable.
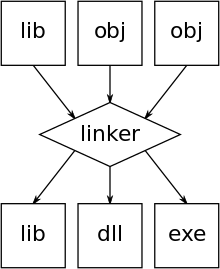
Compiled programs will typically use building blocks (functions) kept in a library of such object code modules.
In traditional compilation, the executable output of the linkers (.exe files or .dll files or a library, see picture) is typically relocatable when run under a general operating system, much like the object code modules are but with the difference that this relocation is done dynamically at run time, i.e. when the program is loaded for execution.
A compiler converts source code into binary instruction for a specific processor's architecture, thus making it less portable.
This conversion is made just once, on the developer's environment, and after that the same binary can be distributed to the user's machines where it can be executed without further translation.
The fact that interpreted code can easily be read and copied by humans can be of concern from the point of view of copyright.
Access to variables is also slower in an interpreter because the mapping of identifiers to storage locations must be done repeatedly at run-time rather than at compile time.
[citation needed] Many interpreters do not execute the source code as it stands but convert it into some more compact internal form.
Many BASIC interpreters replace keywords with single byte tokens which can be used to find the instruction in a jump table.
Example data type definitions for the latter, and a toy interpreter for syntax trees obtained from C expressions are shown in the box.
[8][9] There is a spectrum of possibilities between interpreting and compiling, depending on the amount of analysis performed before the program is executed.
Unlike bytecode there is no effective limit on the number of different instructions other than available memory and address space.
[citation needed] In the spectrum between interpreting and compiling, another approach is to transform the source code into an optimized abstract syntax tree (AST), then execute the program following this tree structure, or use it to generate native code just-in-time.
This confers the efficiency of running native code, at the cost of startup time and increased memory use when the bytecode or AST is first compiled.
The earliest published JIT compiler is generally attributed to work on LISP by John McCarthy in 1960.
[15] Adaptive optimization is a complementary technique in which the interpreter profiles the running program and compiles its most frequently executed parts into native code.
Rather than implement the execution of code by virtue of a large switch statement containing every possible bytecode, while operating on a software stack or a tree walk, a template interpreter maintains a large array of bytecode (or any efficient intermediate representation) mapped directly to corresponding native machine instructions that can be executed on the host hardware as key value pairs (or in more efficient designs, direct addresses to the native instructions),[17][18] known as a "Template".
When the particular code segment is executed the interpreter simply loads or jumps to the opcode mapping in the template and directly runs it on the hardware.
[19][20] Due to its design, the template interpreter very strongly resembles a just-in-time compiler rather than a traditional interpreter, however it is technically not a JIT due to the fact that it merely translates code from the language into native calls one opcode at a time rather than creating optimized sequences of CPU executable instructions from the entire code segment.
It was in this way that Donald Knuth developed the TANGLE interpreter for the language WEB of the de-facto standard TeX typesetting system.
The more features implemented by the same feature in the host language, the less control the programmer of the interpreter has; for example, a different behavior for dealing with number overflows cannot be realized if the arithmetic operations are delegated to corresponding operations in the host language.
[21] Much research on self-interpreters (particularly reflective interpreters) has been conducted in the Scheme programming language, a dialect of Lisp.
Microcode is a very commonly used technique "that imposes an interpreter between the hardware and the architectural level of a computer".
More extensive microcoding allows small and simple microarchitectures to emulate more powerful architectures with wider word length, more execution units and so on, which is a relatively simple way to achieve software compatibility between different products in a processor family.
Even a non microcoding computer processor itself can be considered to be a parsing immediate execution interpreter that is written in a general purpose hardware description language such as VHDL to create a system that parses the machine code instructions and immediately executes them.