Semantic Web
To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF)[2] and Web Ontology Language (OWL)[3] are used.
According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries.
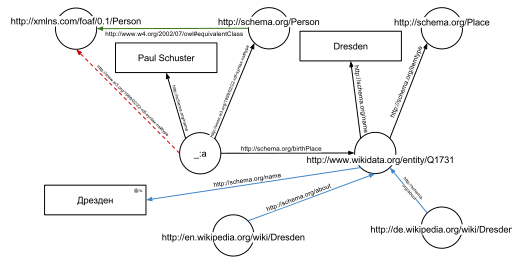
The following HTML fragment shows how a small graph is being described, in RDFa-syntax using a schema.org vocabulary and a Wikidata ID: The example defines the following five triples (shown in Turtle syntax).
Additionally to the edges given in the involved documents explicitly, edges can be automatically inferred: the triple from the original RDFa fragment and the triple from the document at https://schema.org/Person (green edge in the figure) allow to infer the following triple, given OWL semantics (red dashed line in the second Figure): The concept of the semantic network model was formed in the early 1960s by researchers such as the cognitive scientist Allan M. Collins, linguist Ross Quillian and psychologist Elizabeth F. Loftus as a form to represent semantically structured knowledge.
Data, such as calendars, address books, playlists, and spreadsheets are presented using an application program that lets them be viewed, searched, and combined.
In the examples below, the field names "keywords", "description" and "author" are assigned values such as "computing", and "cheap widgets for sale" and "John Doe".
Because of this metadata tagging and categorization, other computer systems that want to access and share this data can easily identify the relevant values.
With HTML and a tool to render it (perhaps web browser software, perhaps another user agent), one can create and present a page that lists items for sale.
Microformats extend HTML syntax to create machine-readable semantic markup about objects including people, organizations, events and products.
by research topics and scientific fields by the projects OpenAlex,[19][20][21] Wikidata and Scholia which are under development and provide APIs, Web-pages, feeds and graphs for various semantic queries.
Using advanced artificial and ambient intelligence, the internet of things, trusted blockchain transactions, virtual worlds and XR capabilities, digital and real objects and environments are fully integrated and communicate with each other, enabling truly intuitive, immersive experiences, seamlessly blending the physical and digital worlds".
[28] Many of the techniques mentioned here will require extensions to the Web Ontology Language (OWL) for example to annotate conditional probabilities.
[5] The collection, structuring and recovery of linked data are enabled by technologies that provide a formal description of concepts, terms, and relationships within a given knowledge domain.
Business applications include: In a corporation, there is a closed group of users and the management is able to enforce company guidelines like the adoption of specific ontologies and use of semantic annotation.
Compared to the public Semantic Web there are lesser requirements on scalability and the information circulating within a company can be more trusted in general; privacy is less of an issue outside of handling of customer data.
Critics question the basic feasibility of a complete or even partial fulfillment of the Semantic Web, pointing out both difficulties in setting it up and a lack of general-purpose usefulness that prevents the required effort from being invested.
[...] These abstractions are taught to computer scientists generally and knowledge engineers specifically but do not match the similar natural language meaning of being a "type of" something.
[47] The practical constraints toward adoption have appeared less challenging where domain and scope is more limited than that of the general public and the World-Wide Web.
[47] Finally, Marshall and Shipman see pragmatic problems in the idea of (Knowledge Navigator-style) intelligent agents working in the largely manually curated Semantic Web:[46] In situations in which user needs are known and distributed information resources are well described, this approach can be highly effective; in situations that are not foreseen and that bring together an unanticipated array of information resources, the Google approach is more robust.
[...] cost-benefit tradeoffs can work in favor of specially-created Semantic Web metadata directed at weaving together sensible well-structured domain-specific information resources; close attention to user/customer needs will drive these federations if they are to be successful.Cory Doctorow's critique ("metacrap")[48] is from the perspective of human behavior and personal preferences.
In addition, the issue has also been raised that, with the use of FOAF files and geolocation meta-data, there would be very little anonymity associated with the authorship of articles on things such as a personal blog.
Another criticism of the semantic web is that it would be much more time-consuming to create and publish content because there would need to be two formats for one piece of data: one for human viewing and one for machines.
Another argument in defense of the feasibility of semantic web is the likely falling price of human intelligence tasks in digital labor markets, such as Amazon's Mechanical Turk.
The GRDDL (Gleaning Resource Descriptions from Dialects of Language) mechanism allows existing material (including microformats) to be automatically interpreted as RDF, so publishers only need to use a single format, such as HTML.