Spectral clustering
In application to image segmentation, spectral clustering is known as segmentation-based object categorization.
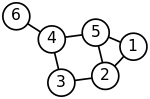
Spectral clustering is well known to relate to partitioning of a mass-spring system, where each mass is associated with a data point and each spring stiffness corresponds to a weight of an edge describing a similarity of the two related data points, as in the spring system.
Specifically, the classical reference [1] explains that the eigenvalue problem describing transversal vibration modes of a mass-spring system is exactly the same as the eigenvalue problem for the graph Laplacian matrix defined as where
The masses that are tightly connected by the springs in the mass-spring system evidently move together from the equilibrium position in low-frequency vibration modes, so that the components of the eigenvectors corresponding to the smallest eigenvalues of the graph Laplacian can be used for meaningful clustering of the masses.
For example, assuming that all the springs and the masses are identical in the 2-dimensional spring system pictured, one would intuitively expect that the loosest connected masses on the right-hand side of the system would move with the largest amplitude and in the opposite direction to the rest of the masses when the system is shaken — and this expectation will be confirmed by analyzing components of the eigenvectors of the graph Laplacian corresponding to the smallest eigenvalues, i.e., the smallest vibration frequencies.
A popular normalized spectral clustering technique is the normalized cuts algorithm or Shi–Malik algorithm introduced by Jianbo Shi and Jitendra Malik,[2] commonly used for image segmentation.
corresponding to the second-smallest eigenvalue of the symmetric normalized Laplacian defined as The vector
is also the eigenvector corresponding to the second-largest eigenvalue of the symmetrically normalized adjacency matrix
The random walk (or left) normalized Laplacian is defined as and can also be used for spectral clustering.
corresponding to the largest eigenvalue of the random walk normalized adjacency matrix
of selected eigenvectors, mapping — called spectral embedding — of the original
This sign-based approach follows the intuitive explanation of spectral clustering via the mass-spring model — in the low frequency vibration mode that the Fiedler vector
represents, one cluster data points identified with mutually strongly connected masses would move together in one direction, while in the complement cluster data points identified with remaining masses would move together in the opposite direction.
The algorithm can be used for hierarchical clustering by repeatedly partitioning the subsets in the same fashion.
has not already been explicitly constructed, the efficiency of spectral clustering may be improved if the solution to the corresponding eigenvalue problem is performed in a matrix-free fashion (without explicitly manipulating or even computing the similarity matrix), as in the Lanczos algorithm.
Preconditioning is a key technology accelerating the convergence, e.g., in the matrix-free LOBPCG method.
, it is important to estimate the memory footprint and compute time, or number of arithmetic operations (AO) performed, as a function of
No matter the algorithm of the spectral clustering, the two main costly items are the construction of the graph Laplacian and determining its
The need to construct the graph Laplacian is common for all distance- or correlation-based clustering methods.
The construction can be performed matrix-free, i.e., without explicitly forming the matrix of the graph Laplacian and no AO.
It can also be performed in-place of the adjacency matrix without increasing the memory footprint.
Thus, instead of computing the eigenvectors corresponding to the smallest eigenvalues of the normalized Laplacian, one can equivalently compute the eigenvectors corresponding to the largest eigenvalues of the normalized adjacency matrix, without even talking about the Laplacian matrix.
Naive constructions of the graph adjacency matrix, e.g., using the RBF kernel, make it dense, thus requiring
Algorithms to construct the graph adjacency matrix as a sparse matrix are typically based on a nearest neighbor search, which estimate or sample a neighborhood of a given data point for nearest neighbors, and compute non-zero entries of the adjacency matrix by comparing only pairs of the neighbors.
) matrix of selected eigenvectors of the graph Laplacian is normally proportional to the cost of multiplication of the
Moreover, matrix-free eigenvalue solvers such as LOBPCG can efficiently run in parallel, e.g., on multiple GPUs with distributed memory, resulting not only in high quality clusters, which spectral clustering is famous for, but also top performance.
In particular, it can be described in the context of kernel clustering methods, which reveals several similarities with other approaches.
[18] Ravi Kannan, Santosh Vempala and Adrian Vetta[19] proposed a bicriteria measure to define the quality of a given clustering.
[20][21][22][23][24][2][25] Spectral clustering as a machine learning method was popularized by Shi & Malik[2] and Ng, Jordan, & Weiss.
For instance, networks with stronger spectral partitions take longer to converge in opinion-updating models used in sociology and economics.