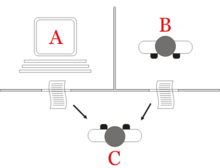
Turing test
Initially in an article in The Economist Google Research Fellow Blaise Agüera y Arcas said the chatbot had demonstrated a degree of understanding of social relationships.
Descartes fails to consider the possibility that future automata might be able to overcome such insufficiency, and so does not propose the Turing test as such, even if he prefigures its conceptual framework and criterion.
[33] It was a common topic among the members of the Ratio Club, an informal group of British cybernetics and electronics researchers that included Alan Turing.
(Huma Shah argues that this two-human version of the game was presented by Turing only to introduce the reader to the machine-human question-answer test.
[6] John Searle's 1980 paper Minds, Brains, and Programs proposed the "Chinese room" thought experiment and argued that the Turing test could not be used to determine if a machine could think.
[49] The Loebner Prize, now reported as defunct,[50] provided an annual platform for practical Turing tests with the first competition held in November 1991.
As Loebner described it, one reason the competition was created is to advance the state of AI research, at least in part, because no one had taken steps to implement the Turing test despite 40 years of discussing it.
[52] The first Loebner Prize competition in 1991 led to a renewed discussion of the viability of the Turing test and the value of pursuing it, in both the popular press[53] and academia.
[54] The first contest was won by a mindless program with no identifiable intelligence that managed to fool naïve interrogators into making the wrong identification.
[59][60] Saul Traiger argues that there are at least three primary versions of the Turing test, two of which are offered in "Computing Machinery and Intelligence" and one that he describes as the "Standard Interpretation".
[65] According to Huma Shah, Turing himself was concerned with whether a machine could think and was providing a simple method to examine this: through human-machine question-answer sessions.
[66] Shah argues the imitation game which Turing described could be practicalized in two different ways: a) one-to-one interrogator-machine test, and b) simultaneous comparison of a machine with a human, both questioned in parallel by an interrogator.
Shlomo Danziger[70] promotes a socio-technological interpretation, according to which Turing saw the imitation game not as an intelligence test but as a technological aspiration - one whose realization would likely involve a change in society's attitude toward machines.
[7] An experimental study looking at Gricean maxim violations using transcripts of Loebner's one-to-one (interrogator-hidden interlocutor) Prize for AI contests between 1994 and 1999, Ayse Saygin found significant differences between the responses of participants who knew and did not know about computers being involved.
The philosophy of mind, psychology, and modern neuroscience have been unable to provide definitions of "intelligence" and "thinking" that are sufficiently precise and general to be applied to machines.
It is a limited form of Turing's question-answer game which compares the machine against the abilities of experts in specific fields such as literature or chemistry.
As a Cambridge honours graduate in mathematics, Turing might have been expected to propose a test of computer intelligence requiring expert knowledge in some highly technical field, and thus anticipating a more recent approach to the subject.
Given the status of human sexual dimorphism as one of the most ancient of subjects, it is thus implicit in the above scenario that the questions to be answered will involve neither specialised factual knowledge nor information processing technique.
Numerous experts in the field, including cognitive scientist Gary Marcus, insist that the Turing test only shows how easy it is to fool humans and is not an indication of machine intelligence.
The example of ELIZA suggests that a machine passing the test may be able to simulate human conversational behaviour by following a simple (but large) list of mechanical rules, without thinking or having a mind at all.
[46] His Chinese room argument is intended to show that, even if the Turing test is a good operational definition of intelligence, it may not indicate that the machine has a mind, consciousness, or intentionality.
Erik Brynjolfsson has called this "The Turing Trap"[97] and argued that there are currently excess incentives for creating machines that imitate rather than augment humans.
Before being allowed to perform some action on a website, the user is presented with alphanumerical characters in a distorted graphic image and asked to type them out.
The rationale is that software sufficiently sophisticated to read and reproduce the distorted image accurately does not exist (or is not available to the average user), so any system able to do so is likely to be a human.
He proposes a test in which the machine is confronted with philosophical questions that do not depend on any prior knowledge and yet require self-reflection to be answered appropriately.
and further the letter states: "Before synthetic patient identities become a public health problem, the legitimate EHR market might benefit from applying Turing Test-like techniques to ensure greater data reliability and diagnostic value.
[111] The organisers of the Hutter Prize believe that compressing natural language text is a hard AI problem, equivalent to passing the Turing test.
[116] Taking advantage of large language models, in 2023 the research company AI21 Labs created an online social experiment titled "Human or Not?
[122] In parallel to the 2008 Loebner Prize held at the University of Reading,[123] the Society for the Study of Artificial Intelligence and the Simulation of Behaviour (AISB), hosted a one-day symposium to discuss the Turing test, organised by John Barnden, Mark Bishop, Huma Shah and Kevin Warwick.
[124] The speakers included the Royal Institution's Director Baroness Susan Greenfield, Selmer Bringsjord, Turing's biographer Andrew Hodges, and consciousness scientist Owen Holland.