Causal inference
Causal inference is the process of determining the independent, actual effect of a particular phenomenon that is a component of a larger system.
The first step of causal inference is to formulate a falsifiable null hypothesis, which is subsequently tested with statistical methods.
[citation needed] A frequently sought after standard of causal inference is an experiment wherein treatment is randomly assigned but all other confounding factors are held constant.
Results of a 2020 review of methods for causal inference found that using existing literature for clinical training programs can be challenging.
This is because published articles often assume an advanced technical background, they may be written from multiple statistical, epidemiological, computer science, or philosophical perspectives, methodological approaches continue to expand rapidly, and many aspects of causal inference receive limited coverage.
Epidemiology studies patterns of health and disease in defined populations of living beings in order to infer causes and effects.
An association between an exposure to a putative risk factor and a disease may be suggestive of, but is not equivalent to causality because correlation does not imply causation.
[independent source needed] Linking the exposure to molecular pathologic signatures of the disease can help to assess causality.
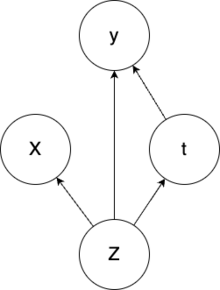
[9] While the above scenario could be modelled without the use of the hidden confounder(Z) we would lose the insight that the symptoms a patient together with other factors impacts both the treatment assignment and the outcome.
Determination of cause and effect from joint observational data for two time-independent variables, say X and Y, has been tackled using asymmetry between evidence for some model in the directions, X → Y and Y → X.
Political science was significantly influenced by the publication of Designing Social Inquiry, by Gary King, Robert Keohane, and Sidney Verba, in 1994.
King, Keohane, and Verba recommend that researchers apply both quantitative and qualitative methods and adopt the language of statistical inference to be clearer about their subjects of interest and units of analysis.
[15][16] Proponents of quantitative methods have also increasingly adopted the potential outcomes framework, developed by Donald Rubin, as a standard for inferring causality.
Sociologist Herbert Smith and Political Scientists James Mahoney and Gary Goertz have cited the observation of Paul Holland, a statistician and author of the 1986 article "Statistics and Causal Inference", that statistical inference is most appropriate for assessing the "effects of causes" rather than the "causes of effects".
[citation needed] On longer timescales, persistence studies uses causal inference to link historical events to later political, economic and social outcomes.
[22] Despite the difficulties inherent in determining causality in economic systems, several widely employed methods exist throughout those fields.
[23] Theorists can presuppose a mechanism believed to be causal and describe the effects using data analysis to justify their proposed theory.
For example, theorists can use logic to construct a model, such as theorizing that rain causes fluctuations in economic productivity but that the converse is not true.
[29] However, there are limits to sensitivity analysis' ability to prevent the deleterious effects of multicollinearity, especially in the social sciences, where systems are complex.
These weaknesses can be attributed both to the inherent difficulty of determining causal relations in complex systems but also to cases of scientific malpractice.
As scientific study is a broad topic, there are theoretically limitless ways to have a causal inference undermined through no fault of a researcher.
Nonetheless, there remain concerns among scientists that large numbers of researchers do not perform basic duties or practice sufficiently diverse methods in causal inference.
[35] Critics of widely practiced methodologies argue that researchers have engaged statistical manipulation in order to publish articles that supposedly demonstrate evidence of causality but are actually examples of spurious correlation being touted as evidence of causality: such endeavors may be referred to as P hacking.