Constraint grammar
Linguist-written, context-dependent rules are compiled into a grammar that assigns grammatical tags ("readings") to words or other tokens in running text.
Typical tags address lemmatisation (lexeme or base form), inflexion, derivation, syntactic function, dependency, valency, case roles, semantic type etc.
Typical CGs consist of thousands of rules, that are applied set-wise in progressive steps, covering ever more advanced levels of analysis.
CG methodology has also been used in a number of language technology applications, such as spell checkers and machine translation systems.
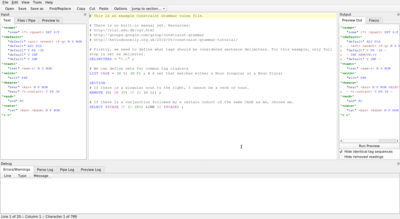
Below is a possible example analysis of ", and X was like “" in the input format expected by VISL CG-3: This snippet shows 5 cohorts, each with one or more readings.
Rules are ordered within sections, which gives more predictability when writing grammars, but at the cost of slower parsing and the possibility of endless loops.
There have been experimental open-source FST-based reimplementations of CG-2 that for small grammars reach the speed of VISL CG-3, if not mdis.