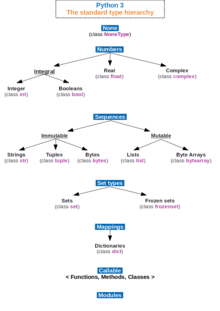
Data structure
[5] Different types of data structures are suited to different kinds of applications, and some are highly specialized to specific tasks.
For example, relational databases commonly use B-tree indexes for data retrieval,[6] while compiler implementations usually use hash tables to look up identifiers.
This approach to data structuring has profound implications for the efficiency and scalability of algorithms.
For instance, the contiguous memory allocation in arrays facilitates rapid access and modification operations, leading to optimized performance in sequential data processing scenarios.
This observation motivates the theoretical concept of an abstract data type, a data structure that is defined indirectly by the operations that may be performed on it, and the mathematical properties of those operations (including their space and time cost).
Modern languages also generally support modular programming, the separation between the interface of a library module and its implementation.
Some provide opaque data types that allow clients to hide implementation details.