Homogeneity and heterogeneity (statistics)
However, questions of homogeneity apply to all aspects of the statistical distributions, including the location parameter.
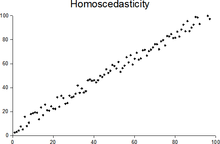
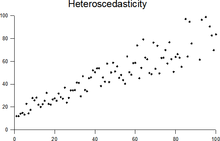
[1][2][3] Assuming a variable is homoscedastic when in reality it is heteroscedastic (/ˌhɛtəroʊskəˈdæstɪk/) results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.
While the ordinary least squares estimator is still unbiased in the presence of heteroscedasticity, it is inefficient and inference based on the assumption of homoskedasticity is misleading.
[6] Because heteroscedasticity concerns expectations of the second moment of the errors, its presence is referred to as misspecification of the second order.
There should then be a later stage of analysis to examine whether the errors in the predictions from the regression behave in the same way across the dataset.
Assessing the homogeneity of the population would involve looking to see whether the responses of certain identifiable subpopulations differ from those of others.
A test for homogeneity, in the sense of exact equivalence of statistical distributions, can be based on an E-statistic.