mitochondria; also formerly chondriosome.Also M phase.Also somatic crossing over.Also phosphorodiamidate Morpholino oligomer.Also polylinker.
Also negative regulation.Sometimes used interchangeably with nucleobase or simply base.Also non-standard amino acid.Also point-nonsense mutation.Also nonsynonymous substitution or replacement mutation.Also amine terminus and amino terminus.Also nuclear localization sequence.Sometimes used interchangeably with nitrogenous base or simply base.Also prokaryon.Also karyoplasm.Also karyolymph or nuclear hyaloplasm.Also nucleoside monophosphate (NMP).pl.
nuclei Also abbreviated oligo.Also one gene–one protein or one gene–one enzyme.Also umber.Also replication origin or simply origin.Also osmotic stress.
Also synthesis phase or synthetic phase.Also selfish DNA or parasitic DNA.Denoted in shorthand with the symbol p.Also vegetal cell or soma.Also intergenic spacer (IGS) or non-transcribed spacer (NTS).Also hairpin or hairpin loop.Also termination codon.Also sumoylation.Also symplasm; pl.
Also Goldberg-Hogness box.Also antisense strand, negative (-) sense strand, and noncoding strand.Also deoxythymidine.Also 5-methyluracil.Also transcription initiation site.Formerly referred to as soluble RNA (sRNA).Also transporter.Also transposon.Also triacylglycerol and triacylglyceride.Also tropic movement.Also turgidity.
The structure of a typical mature protein-coding
messenger RNA
or
mRNA
, drawn approximately to scale. The coding sequence (green) is bounded by
untranslated regions
at both the
5'-end
(yellow) and the
3'-end
(pink). Prior to export from the nucleus, a
5' cap
(red) and a
3' poly(A) tail
(black) are added to help stabilize the mRNA and prevent its degradation by ribonucleases.
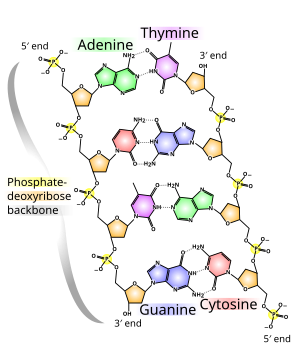
A defining element of nucleic acid structure is the linear chain of alternating
sugars
(orange) and
phosphates
(yellow) known as the
phosphate backbone
, which acts as a scaffold to which
nucleobases
are attached. The phosphorus atom of each phosphate group forms two
ester bonds
to specific carbon atoms within the pentose sugars—
ribose
in RNA and
deoxyribose
in DNA—of two adjacent nucleosides.
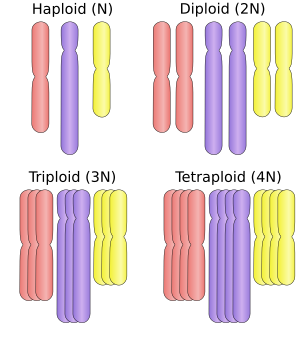
A cell's
ploidy
level is defined by the number of copies it has of each specific chromosome: if the cell has two copies of each of three distinct chromosomes, it is said to be
diploid
(2N).
A double-stranded DNA molecule containing the sequence
GAATTC
and its palindromic complement
CTTAAG
, a
restriction site
for the bacterial enzyme
EcoRI
, is recognized and
cut or "digested"
in the manner shown here, with the enzyme breaking phosphodiester bonds in the backbones of both strands and leaving behind
"sticky" overhangs
at the ends of each of the now separate molecules.
Three different modes of
DNA replication
. In
semiconservative replication
, each of the two daughter molecules is built from one of the original parental strands and one newly synthesized strand. In
conservative replication
, the original parent molecule remains intact while the replicated molecule is composed of two newly synthesized strands. In
dispersive replication
, each of the daughter molecules is an uneven mix of old and new, with some segments consisting of the two parental strands and others consisting of two newly synthesized strands. Only semiconservative replication occurs naturally.
A
sequence logo
depicts the statistical frequency with which each nucleobase (or amino acid) occurs within a given
sequence
. Each position in the sequence is represented by a vertical stack of letters; the total height of the stack indicates the degree of
consensus
at that position between all of the aligned sequences, and the height of each individual letter in the stack indicates the proportion of the aligned sequences having that nucleobase at that position. A single very large letter filling most of the stack indicates that most or all of the aligned sequences have that particular nucleobase at that position.
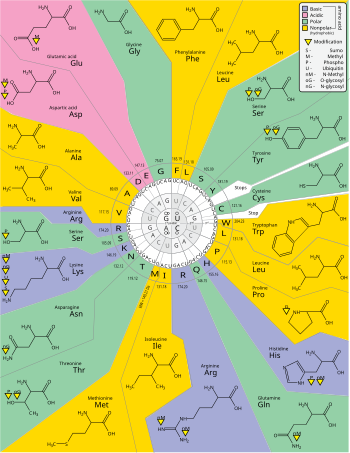
The
standard genetic code
specifies a set of 20 different
amino acids
from triplet arrangements of the four different
RNA
nucleobases
(
A
,
G
,
C
, and
U
). To read this chart, choose one of the four letters in the innermost ring and then move outward, adding two more letters to complete a
codon
triplet: a total of 64 unique codons can be made this way, 61 of which signal the addition of one of the 20 amino acids (identified by single-letter abbreviation as well as by full name and chemical structure) to a nascent
peptide
chain, while the remaining three codons are
stop codons
signalling the termination of translation. Also indicated are some of the chemical properties of the amino acids and the various ways in which they can be modified.
A simplified diagram of
transcription
. RNA polymerase (RNAP) synthesizes an RNA transcript (blue) in the 5'-to-3' direction, using one of the DNA strands as a
template
, while a complex of multiple
transcription factors
binds to a
promoter
upstream of the gene.