Structural equation modeling
Structural equation modeling (SEM) is a diverse set of methods used by scientists for both observational and experimental research.
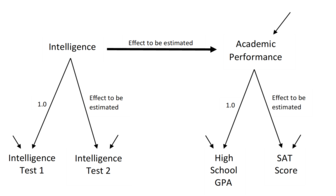
[11] A great advantage of SEM is that all of these measurements and tests occur simultaneously in one statistical estimation procedure, where all the model coefficients are calculated using all information from the observed variables.
[12] Structural equation modeling (SEM) began differentiating itself from correlation and regression when Sewall Wright provided explicit causal interpretations for a set of regression-style equations based on a solid understanding of the physical and physiological mechanisms producing direct and indirect effects among his observed variables.
In 1987 Hayduk[7] provided the first book-length introduction to structural equation modeling with latent variables, and this was soon followed by Bollen's popular text (1989).
Early Cowles Commission work on simultaneous equations estimation centered on Koopman and Hood's (1953) algorithms from transport economics and optimal routing, with maximum likelihood estimation, and closed form algebraic calculations, as iterative solution search techniques were limited in the days before computers.
The factor-structured portion of the model incorporated measurement errors which permitted measurement-error-adjustment, though not necessarily error-free estimation, of effects connecting different postulated latent variables.
Wright's path analysis influenced Hermann Wold, Wold's student Karl Jöreskog, and Jöreskog's student Claes Fornell, but SEM never gained a large following among U.S. econometricians, possibly due to fundamental differences in modeling objectives and typical data structures.
The prolonged separation of SEM's economic branch led to procedural and terminological differences, though deep mathematical and statistical connections remain.
[5] Discussions comparing and contrasting various SEM approaches are available[25][26] highlighting disciplinary differences in data structures and the concerns motivating economic models.
Judea Pearl[5] extended SEM from linear to nonparametric models, and proposed causal and counterfactual interpretations of the equations.
Building or specifying a model requires attending to: Structural equation models attempt to mirror the worldly forces operative for causally homogeneous cases – namely cases enmeshed in the same worldly causal structures but whose values on the causes differ and who therefore possess different values on the outcome variables.
The "simplifications" are achieved by implicitly introducing default program "assumptions" about model features with which users supposedly need not concern themselves.
Hence model assessments consider: Research claiming to test or "investigate" a theory requires attending to beyond-chance model-data inconsistency.
A small χ2 probability reports it would be unlikely for the current data to have arisen if the modeled structure constituted the real population causal forces – with the remaining differences attributed to random sampling variations.
Researchers confronting data-inconsistent models can easily free coefficients the modification indices report as likely to produce substantial improvements in fit.
A cautionary instance was provided by Browne, MacCallum, Kim, Anderson, and Glaser who addressed the mathematics behind why the χ2 test can have (though it does not always have) considerable power to detect model misspecification.
The fault was in Browne, MacCallum, and the other authors forgetting, neglecting, or overlooking, that the amount of ill fit cannot be trusted to correspond to the nature, location, or seriousness of problems in a model's specification.
Some kinds of important misspecifications cannot be detected by χ2,[38] so any amount of ill fit beyond what might be reasonably produced by random variations warrants report and consideration.
This logical weakness renders all fit indices "unhelpful" whenever a structural equation model is significantly inconsistent with the data,[39] but several forces continue to propagate fit-index use.
For example, Dag Sorbom reported that when someone asked Karl Joreskog, the developer of the first structural equation modeling program, "Why have you then added GFI?"
Introductory statistics texts usually recommend replacing the term "accept" with "failed to reject the null hypothesis" to acknowledge the possibility of Type II error.
Data’s ability to speak against a postulated model is progressively eroded with each unwarranted inclusion of a “modification index suggested” effect or error covariance.
SEM interpretations encourage understanding how multiple worldly causal pathways can work in coordination, or independently, or even counteract one another.
To be dependable, the model should investigate academically informative causal structures, fit applicable data with understandable estimates, and not include vacuous coefficients.
Researchers from the factor analytic tradition commonly attempt to reduce sets of multiple indicators to fewer, more manageable, scales or factor-scores for later use in path-structured models.
This constitutes a stepwise process with the initial measurement step providing scales or factor-scores which are to be used later in a path-structured model.
The simmering, sometimes boiling, discussions resulted in a special issue of the journal Structural Equation Modeling focused on a target article by Hayduk and Glaser[21] followed by several comments and a rejoinder,[22] all made freely available, thanks to the efforts of George Marcoulides.
Hayduk and Littvay (2012)[35] discussed how to think about, defend, and adjust for measurement error, when using only a single indicator for each modeled latent variable.
Single indicators have been used effectively in SE models for a long time,[54] but controversy remains only as far away as a reviewer who has considered measurement from only the factor analytic perspective.
Though declining, traces of these controversies are scattered throughout the SEM literature, and you can easily incite disagreement by asking: What should be done with models that are significantly inconsistent with the data?