Biopython
The Biopython project is an open-source collection of non-commercial Python tools for computational biology and bioinformatics, created by an international association of developers.
Biopython is one of a number of Bio* projects designed to reduce code duplication in computational biology.
[7] It was developed during a similar time frame and with analogous goals to other projects that added bioinformatics capabilities to their respective programming languages, including BioPerl, BioRuby and BioJava.
Early developers on the project included Jeff Chang, Andrew Dalke and Brad Chapman, though over 100 people have made contributions to date.
[9] The initial scope of Biopython involved accessing, indexing and processing biological sequence files.
While this is still a major focus, over the following years added modules have extended its functionality to cover additional areas of biology (see Key features and examples).
For example, Seq and SeqRecord objects can be manipulated via slicing, in a manner similar to Python's strings and lists.
Biopython can read and write to a number of common sequence formats, including FASTA, FASTQ, GenBank, Clustal, PHYLIP and NEXUS.
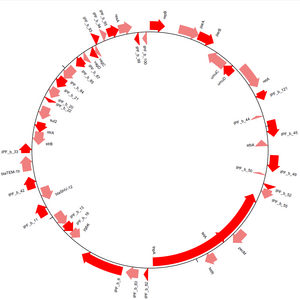
[15] Sequences can be drawn in a linear or circular form (see Figure 3), and many output formats are supported, including PDF and PNG.
The Bio.PopGen module adds support to Biopython for Genepop, a software package for statistical analysis of population genetics.