Classic RISC pipeline
Those CPUs were: MIPS, SPARC, Motorola 88000, and later the notional CPU DLX invented for education.
The term "latency" is used in computer science often and means the time from when an operation starts until it completes.
The program counter (PC) is a register that holds the address that is presented to the instruction memory.
Some architectures made use of the Arithmetic logic unit (ALU) in the Execute stage, at the cost of slightly decreased instruction throughput.
The decode stage ended up with quite a lot of hardware: MIPS has the possibility of branching if two registers are equal, so a 32-bit-wide AND tree runs in series after the register file read, making a very long critical path through this stage (which means fewer cycles per second).
Instructions on these simple RISC machines can be divided into three latency classes according to the type of the operation: If data memory needs to be accessed, it is done in this stage.
On silicon, many implementations of memory cells will not operate correctly when read and written at the same time.
Hennessy and Patterson coined the term hazard for situations where instructions in a pipeline would produce wrong answers.
It is simple to resolve this conflict by designing a specialized branch target adder into the decode stage.
In the classic RISC pipeline, Data hazards are avoided in one of two ways: Bypassing is also known as operand forwarding.
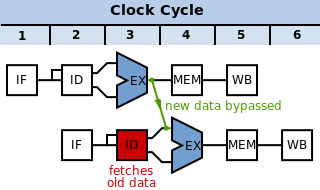
Therefore, the value read from the register file and passed to the ALU (in the Execute stage of the AND operation, red box) is incorrect.
Instead, we must pass the data that was computed by SUB back to the Execute stage (i.e. to the red circle in the diagram) of the AND operation before it is normally written-back.
In the case above, the data is passed forward (by the time the AND is ready for the register in the ALU, the SUB has already computed it).
To resolve this would require the data from memory to be passed backwards in time to the input to the ALU.
This causes quite a performance hit, as the processor spends a lot of time processing nothing, but clock speeds can be increased as there is less forwarding logic to wait for.
This data hazard can be detected quite easily when the program's machine code is written by the compiler.
The Stanford MIPS machine relied on the compiler to add the NOP instructions in this case, rather than having the circuitry to detect and (more taxingly) stall the first two pipeline stages.
The stall hardware, although expensive, was put back into later designs to improve instruction cache hit rate, at which point the acronym no longer made sense.
Numbers greater than the maximum possible encoded value have their most significant bits chopped off until they fit.
But the programmer, especially if programming in a language supporting large integers (e.g. Lisp or Scheme), may not want wrapping arithmetic.
The most common kind of software-visible exception on one of the classic RISC machines is a TLB miss.
When an exception is detected, the following instructions (earlier in the pipeline) are marked as invalid, and as they flow to the end of the pipe their results are discarded.
To make it easy (and fast) for the software to fix the problem and restart the program, the CPU must take a precise exception.
To take precise exceptions, the CPU must commit changes to the software visible state in the program order.
In these cases, the CPU must suspend operation until the cache can be filled with the necessary data, and then must resume execution.
This signal, when activated, prevents instructions from advancing down the pipeline, generally by gating off the clock to the flip-flops at the start of each stage.
The disadvantage of this strategy is that there are a large number of flip flops, so the global stall signal takes a long time to propagate.