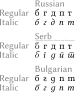Cyrillic script
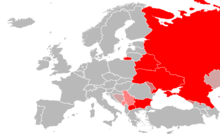
As of 2019[update], around 250 million people in Eurasia use Cyrillic as the official script for their national languages, with Russia accounting for about half of them.
[14] Modern scholars believe that the Early Cyrillic alphabet was created at the Preslav Literary School, the most important early literary and cultural center of the First Bulgarian Empire and of all Slavs: Unlike the Churchmen in Ohrid, Preslav scholars were much more dependent upon Greek models and quickly abandoned the Glagolitic scripts in favor of an adaptation of the Greek uncial to the needs of Slavic, which is now known as the Cyrillic alphabet.
The literature produced in Old Church Slavonic soon spread north from Bulgaria and became the lingua franca of the Balkans and Eastern Europe.
In 1708–10, the Cyrillic script used in Russia was heavily reformed by Peter the Great, who had recently returned from his Grand Embassy in Western Europe.
[28] The pre-reform letterforms, called 'Полуустав', were notably retained in Church Slavonic and are sometimes used in Russian even today, especially if one wants to give a text a 'Slavic' or 'archaic' feel.
A notable example of such linguistic reform can be attributed to Vuk Stefanović Karadžić, who updated the Serbian Cyrillic alphabet by removing certain graphemes no longer represented in the vernacular and introducing graphemes specific to Serbian (i.e. Љ Њ Ђ Ћ Џ Ј), distancing it from the Church Slavonic alphabet in use prior to the reform.
Today, many languages in the Balkans, Eastern Europe, and northern Eurasia are written in Cyrillic alphabets.
Sometimes different letters were used interchangeably, for example И = І = Ї, as were typographical variants like О = Ѻ.
The Unicode 5.1 standard, released on 4 April 2008, greatly improved computer support for the early Cyrillic and the modern Church Slavonic language.
Peter the Great, Tsar of Russia, mandated the use of westernized letter forms (ru) in the early 18th century.
However, the native typeface terminology in most Slavic languages (for example, in Russian) does not use the words "roman" and "italic" in this sense.
[x] Instead, the nomenclature follows German naming patterns:[citation needed] Similarly to Latin typefaces, italic and cursive forms of many Cyrillic letters (typically lowercase; uppercase only for handwritten or stylish types) are very different from their upright roman types.
[36] Sometimes, uppercase letters may have a different shape as well, e.g. more triangular, Д and Л, like Greek delta Δ and lambda Λ.
Computer fonts typically default to the Central/Eastern, Russian letterforms, and require the use of OpenType Layout (OTL) features to display the Western, Bulgarian or Southern, Serbian/Macedonian forms.
Depending on the choices made by the (computer) font designer, they may either be automatically activated by the local variant locl feature for text tagged with an appropriate language code, or the author needs to opt-in by activating a stylistic set ss## or character variant cv## feature.
These solutions only enjoy partial support and may render with default glyphs in certain software configurations, and the reader may not see the same result as the author intended.
The transition is complete in most of Moldova (except the breakaway region of Transnistria, where Moldovan Cyrillic is official), Turkmenistan, and Azerbaijan.
Uzbekistan still uses both systems, and Kazakhstan has officially begun a transition from Cyrillic to Latin (scheduled to be complete by 2025).
[44] The Zhuang alphabet, used between the 1950s and 1980s in portions of the People's Republic of China, used a mixture of Latin, phonetic, numeral-based, and Cyrillic letters.
Standard Cyrillic-to-Latin transliteration systems include: See also Romanization of Belarusian, Bulgarian, Kyrgyz, Russian, Macedonian and Ukrainian.
[48] Other character encoding systems for Cyrillic: Each language has its own standard keyboard layout, adopted from traditional national typewriters.