Inter-rater reliability
Assessment tools that rely on ratings must exhibit good inter-rater reliability, otherwise they are not valid tests.
It is estimated as the percentage of the time the raters agree in a nominal or categorical rating system.
[3] When the number of categories being used is small (e.g. 2 or 3), the likelihood for 2 raters to agree by pure chance increases dramatically.
Cohen's kappa,[5] which works for two raters, and Fleiss' kappa,[6] an adaptation that works for any fixed number of raters, improve upon the joint probability in that they take into account the amount of agreement that could be expected to occur through chance.
Later extensions of the approach included versions that could handle "partial credit" and ordinal scales.
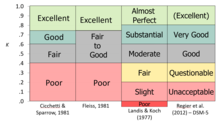
Several authorities have offered "rules of thumb" for interpreting the level of agreement, many of which agree in the gist even though the words are not identical.
[12] There are several types of this and one is defined as, "the proportion of variance of an observation due to between-subject variability in the true scores".
The simple formula, which was given in the previous paragraph and works well for sample size greater than 60,[14] is For smaller sample sizes, another common simplification[15] is However, the most accurate formula (which is applicable for all sample sizes)[14] is Bland and Altman[15] have expanded on this idea by graphing the difference of each point, the mean difference, and the limits of agreement on the vertical against the average of the two ratings on the horizontal.
In this case, the method with the narrow limits of agreement would be superior from a statistical point of view, while practical or other considerations might change this appreciation.
What constitutes narrow or wide limits of agreement or large or small bias is a matter of a practical assessment in each case.
Krippendorff's alpha[16][17] is a versatile statistic that assesses the agreement achieved among observers who categorize, evaluate, or measure a given set of objects in terms of the values of a variable.
It generalizes several specialized agreement coefficients by accepting any number of observers, being applicable to nominal, ordinal, interval, and ratio levels of measurement, being able to handle missing data, and being corrected for small sample sizes.
Alpha emerged in content analysis where textual units are categorized by trained coders and is used in counseling and survey research where experts code open-ended interview data into analyzable terms, in psychometrics where individual attributes are tested by multiple methods, in observational studies where unstructured happenings are recorded for subsequent analysis, and in computational linguistics where texts are annotated for various syntactic and semantic qualities.
Measurement involving ambiguity in characteristics of interest in the rating target are generally improved with multiple trained raters.
Examples include ratings of physician 'bedside manner', evaluation of witness credibility by a jury, and presentation skill of a speaker.
Clearly stated guidelines for rendering ratings are necessary for reliability in ambiguous or challenging measurement scenarios.