Layer (deep learning)
The Convolutional layer[4] is typically used for image analysis tasks.
In this layer, the network detects edges, textures, and patterns.
The Pooling layer[5] is used to reduce the size of data input.
The Recurrent layer is used for text processing with a memory function.
This results in improved scalability and model training.
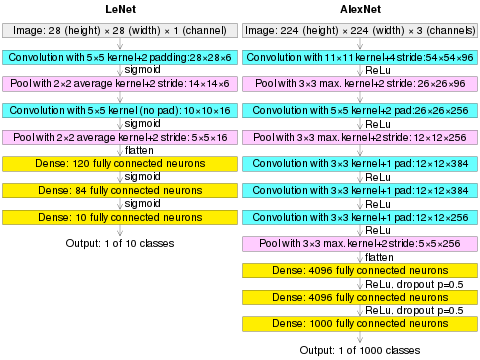
(AlexNet image size should be 227×227×3, instead of 224×224×3, so the math will come out right. The original paper said different numbers, but Andrej Karpathy, the former head of computer vision at Tesla, said it should be 227×227×3 (he said Alex didn't describe why he put 224×224×3). The next convolution should be 11×11 with stride 4: 55×55×96 (instead of 54×54×96). It would be calculated, for example, as: [(input width 227 - kernel width 11) / stride 4] + 1 = [(227 - 11) / 4] + 1 = 55. Since the kernel output is the same length as width, its area is 55×55.)