AlexNet
[1] The original paper's primary result was that the depth of the model was essential for its high performance, which was computationally expensive, but made feasible due to the utilization of graphics processing units (GPUs) during training.
[1] The three formed team SuperVision and submitted AlexNet in the ImageNet Large Scale Visual Recognition Challenge on September 30, 2012.
The architecture influenced a large number of subsequent work in deep learning, especially in applying neural networks to computer vision.
[4] Based on these values, the GPUs were theoretically capable of performing approximately 395 forward passes per second, assuming ideal conditions.
The LeNet-5 (Yann LeCun et al., 1989)[7][8] was trained by supervised learning with backpropagation algorithm, with an architecture that is essentially the same as AlexNet on a small scale.
[9][10] During the 2000s, as GPU hardware improved, some researchers adapted these for general-purpose computing, including neural network training.
", and Jitendra Malik, a sceptic of neural networks, recommended the PASCAL Visual Object Classes challenge.
[17] AlexNet is highly influential, resulting in much subsequent work in using CNNs for computer vision and using GPUs to accelerate deep learning.
The codebase for AlexNet was released under a BSD license, and had been commonly used in neural network research for several subsequent years.


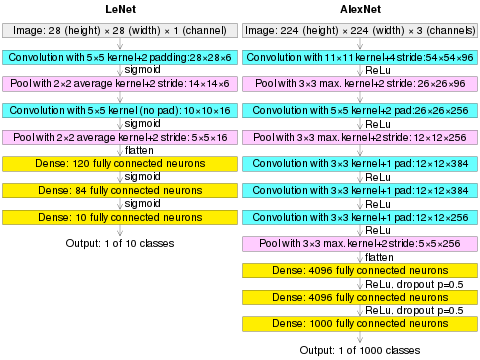
(AlexNet image size should be 227×227×3, instead of 224×224×3, so the math will come out right. The original paper said different numbers, but Andrej Karpathy, the former head of computer vision at Tesla, said it should be 227×227×3 (he said Alex didn't describe why he put 224×224×3). The next convolution should be 11×11 with stride 4: 55×55×96 (instead of 54×54×96). It would be calculated, for example, as: [(input width 227 - kernel width 11) / stride 4] + 1 = [(227 - 11) / 4] + 1 = 55. Since the kernel output is the same length as width, its area is 55×55.)