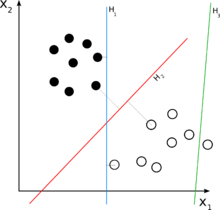
Linear classifier
Such classifiers work well for practical problems such as document classification, and more generally for problems with many variables (features), reaching accuracy levels comparable to non-linear classifiers while taking less time to train and use.
A more complex f might give the probability that an item belongs to a certain class.
Also, linear classifiers often work very well when the number of dimensions in
is typically the number of occurrences of a word in a document (see document-term matrix).
There are two broad classes of methods for determining the parameters of a linear classifier
Examples of such algorithms include: The second set of methods includes discriminative models, which attempt to maximize the quality of the output on a training set.
Additional terms in the training cost function can easily perform regularization of the final model.
Examples of discriminative training of linear classifiers include: Note: Despite its name, LDA does not belong to the class of discriminative models in this taxonomy.
However, its name makes sense when we compare LDA to the other main linear dimensionality reduction algorithm: principal components analysis (PCA).
LDA is a supervised learning algorithm that utilizes the labels of the data, while PCA is an unsupervised learning algorithm that ignores the labels.
[5] Discriminative training often yields higher accuracy than modeling the conditional density functions[citation needed].
However, handling missing data is often easier with conditional density models[citation needed].
Discriminative training of linear classifiers usually proceeds in a supervised way, by means of an optimization algorithm that is given a training set with desired outputs and a loss function that measures the discrepancy between the classifier's outputs and the desired outputs.
[1] Many algorithms exist for solving such problems; popular ones for linear classification include (stochastic) gradient descent, L-BFGS, coordinate descent and Newton methods.