Regularization (mathematics)
By combining both using Bayesian statistics, one can compute a posterior, that includes both information sources and therefore stabilizes the estimation process.
By trading off both objectives, one chooses to be more aligned to the data or to enforce regularization (to prevent overfitting).
The goal of regularization is to encourage models to learn the broader patterns within the data rather than memorizing it.
Techniques like early stopping, L1 and L2 regularization, and dropout are designed to prevent overfitting and underfitting, thereby enhancing the model's ability to adapt to and perform well with new data, thus improving model generalization.
[4] Adds penalty terms to the cost function to discourage complex models: In the context of neural networks, the Dropout technique repeatedly ignores random subsets of neurons during training, which simulates the training of multiple neural network architectures at once to improve generalization.
[4] Empirical learning of classifiers (from a finite data set) is always an underdetermined problem, because it attempts to infer a function of any
Concrete notions of complexity used include restrictions for smoothness and bounds on the vector space norm.
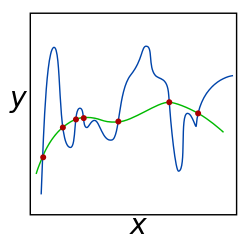
[5][page needed] A theoretical justification for regularization is that it attempts to impose Occam's razor on the solution (as depicted in the figure above, where the green function, the simpler one, may be preferred).
From a Bayesian point of view, many regularization techniques correspond to imposing certain prior distributions on model parameters.
[6] Regularization can serve multiple purposes, including learning simpler models, inducing models to be sparse and introducing group structure[clarification needed] into the learning problem.
Typically in learning problems, only a subset of input data and labels are available, measured with some noise.
) were made with noise, this model may suffer from overfitting and display poor expected error.
Regularization introduces a penalty for exploring certain regions of the function space used to build the model, which can improve generalization.
These techniques are named for Andrey Nikolayevich Tikhonov, who applied regularization to integral equations and made important contributions in many other areas.
The learning problem with the least squares loss function and Tikhonov regularization can be solved analytically.
Intuitively, a training procedure such as gradient descent tends to learn more and more complex functions with increasing iterations.
This can be used to approximate the analytical solution of unregularized least squares, if γ is introduced to ensure the norm is less than one.
The exact solution to the unregularized least squares learning problem minimizes the empirical error, but may fail.
By limiting T, the only free parameter in the algorithm above, the problem is regularized for time, which may improve its generalization.
The algorithm above is equivalent to restricting the number of gradient descent iterations for the empirical risk
In the case of least squares, this problem is known as LASSO in statistics and basis pursuit in signal processing.
A simple example is provided in the figure when the space of possible solutions lies on a 45 degree line.
Elastic net regularization tends to have a grouping effect, where correlated input features are assigned equal weights.
Elastic net regularization is commonly used in practice and is implemented in many machine learning libraries.
The proximal method iteratively performs gradient descent and then projects the result back into the space permitted by
Groups of features can be regularized by a sparsity constraint, which can be useful for expressing certain prior knowledge into an optimization problem.
functions, ideally borrowing strength from the relatedness of tasks, that have predictive power.
An example is predicting blood iron levels measured at different times of the day, where each task represents an individual.
Well-known model selection techniques include the Akaike information criterion (AIC), minimum description length (MDL), and the Bayesian information criterion (BIC).
Alternative methods of controlling overfitting not involving regularization include cross-validation.