Backpropagation
In machine learning, backpropagation[1] is a gradient estimation method commonly used for training a neural network to compute its parameter updates.
Backpropagation computes the gradient of a loss function with respect to the weights of the network for a single input–output example, and does so efficiently, computing the gradient one layer at a time, iterating backward from the last layer to avoid redundant calculations of intermediate terms in the chain rule; this can be derived through dynamic programming.
The Hessian and quasi-Hessian optimizers solve only local minimum convergence problem, and the backpropagation works longer.
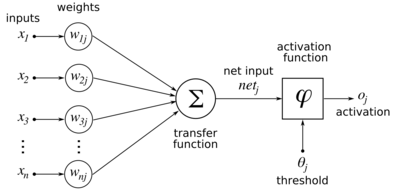
[8] Backpropagation computes the gradient in weight space of a feedforward neural network, with respect to a loss function.
During model training the input–output pair is fixed while the weights vary, and the network ends with the loss function.
Second, it avoids unnecessary intermediate calculations, because at each stage it directly computes the gradient of the weights with respect to the ultimate output (the loss), rather than unnecessarily computing the derivatives of the values of hidden layers with respect to changes in weights
[c] Essentially, backpropagation evaluates the expression for the derivative of the cost function as a product of derivatives between each layer from right to left – "backwards" – with the gradient of the weights between each layer being a simple modification of the partial products (the "backwards propagated error").
is the transpose of the derivative of the output in terms of the input, so the matrices are transposed and the order of multiplication is reversed, but the entries are the same: Backpropagation then consists essentially of evaluating this expression from right to left (equivalently, multiplying the previous expression for the derivative from left to right), computing the gradient at each layer on the way; there is an added step, because the gradient of the weights is not just a subexpression: there's an extra multiplication.
[8] The goal of any supervised learning algorithm is to find a function that best maps a set of inputs to their correct output.
For regression analysis problems the squared error can be used as a loss function, for classification the categorical cross-entropy can be used.
Therefore, the error also depends on the incoming weights to the neuron, which is ultimately what needs to be changed in the network to enable learning.
minimize the loss function, in this case additional constraints are required to converge to a unique solution.
By backpropagation, the steepest descent direction is calculated of the loss function versus the present synaptic weights.
Then, the weights can be modified along the steepest descent direction, and the error is minimized in an efficient way.
The gradient descent method involves calculating the derivative of the loss function with respect to the weights of the network.
(Nevertheless, the ReLU activation function, which is non-differentiable at 0, has become quite popular, e.g. in AlexNet) The first factor is straightforward to evaluate if the neuron is in the output layer, because then
Backpropagation had been derived repeatedly, as it is essentially an efficient application of the chain rule (first written down by Gottfried Wilhelm Leibniz in 1676)[18][19] to neural networks.
[20] In any case, he only studied neurons whose outputs were discrete levels, which only had zero derivatives, making backpropagation impossible.
Yann LeCun et al credits 1950s work by Pontryagin and others in optimal control theory, especially the adjoint state method, for being a continuous-time version of backpropagation.
[21] Hecht-Nielsen[22] credits the Robbins–Monro algorithm (1951)[23] and Arthur Bryson and Yu-Chi Ho's Applied Optimal Control (1969) as presages of backpropagation.
[28] The ADALINE (1960) learning algorithm was gradient descent with a squared error loss for a single layer.
The first multilayer perceptron (MLP) with more than one layer trained by stochastic gradient descent[23] was published in 1967 by Shun'ichi Amari.
[36] He also claimed that "the first practical application of back-propagation was for estimating a dynamic model to predict nationalism and social communications in 1974" by him.
[39] These papers became highly cited, contributed to the popularization of backpropagation, and coincided with the resurging research interest in neural networks during the 1980s.
[42][43] Yann LeCun proposed an alternative form of backpropagation for neural networks in his PhD thesis in 1987.
See the interview with Geoffrey Hinton,[36] who was awarded the 2024 Nobel Prize in Physics for his contributions to the field.
[45] Contributing to the acceptance were several applications in training neural networks via backpropagation, sometimes achieving popularity outside the research circles.
[46] In 1989, Dean A. Pomerleau published ALVINN, a neural network trained to drive autonomously using backpropagation.
[49][50] During the 2000s it fell out of favour[citation needed], but returned in the 2010s, benefiting from cheap, powerful GPU-based computing systems.
[52])[53] Error backpropagation has been suggested to explain human brain event-related potential (ERP) components like the N400 and P600.