Recurrent neural network
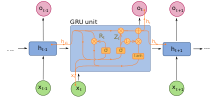
This issue was addressed by the development of the long short-term memory (LSTM) architecture in 1997, making it the standard RNN variant for handling long-term dependencies.
In recent years, Transformers, which rely on self-attention mechanisms instead of recurrence, have become the dominant architecture for many sequence-processing tasks, particularly in natural language processing, due to their superior handling of long-range dependencies and greater parallelizability.
Nevertheless, RNNs remain relevant for applications where computational efficiency, real-time processing, or the inherent sequential nature of data is crucial.
[7][8] In 1933, Lorente de Nó discovered "recurrent, reciprocal connections" by Golgi's method, and proposed that excitatory loops explain certain aspects of the vestibulo-ocular reflex.
[9][10] During 1940s, multiple people proposed the existence of feedback in the brain, which was a contrast to the previous understanding of the neural system as a purely feedforward structure.
In 1993, a neural history compressor system solved a "Very Deep Learning" task that required more than 1000 subsequent layers in an RNN unfolded in time.
[34] Long short-term memory (LSTM) networks were invented by Hochreiter and Schmidhuber in 1995 and set accuracy records in multiple applications domains.
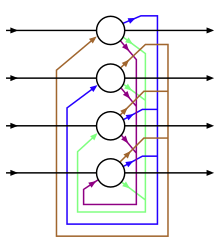
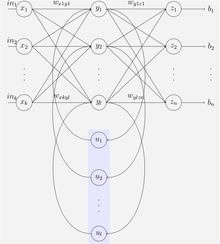
The illustration to the right may be misleading to many because practical neural network topologies are frequently organized in "layers" and the drawing gives that appearance.
Thus the network can maintain a sort of state, allowing it to perform tasks such as sequence-prediction that are beyond the power of a standard multilayer perceptron.
That is, LSTM can learn tasks that require memories of events that happened thousands or even millions of discrete time steps earlier.
[56] LSTM works even given long delays between significant events and can handle signals that mix low and high-frequency components.
Recently, stochastic BAM models using Markov stepping were optimized for increased network stability and relevance to real-world applications.
The combined system is analogous to a Turing machine or Von Neumann architecture but is differentiable end-to-end, allowing it to be efficiently trained with gradient descent.
[75] Neural network pushdown automata (NNPDA) are similar to NTMs, but tapes are replaced by analog stacks that are differentiable and trained.
A more computationally expensive online variant is called "Real-Time Recurrent Learning" or RTRL,[78][79] which is an instance of automatic differentiation in the forward accumulation mode with stacked tangent vectors.
[36] This problem is also solved in the independently recurrent neural network (IndRNN)[87] by reducing the context of a neuron to its own past state and the cross-neuron information can then be explored in the following layers.
The on-line algorithm called causal recursive backpropagation (CRBP), implements and combines BPTT and RTRL paradigms for locally recurrent networks.
This fact improves the stability of the algorithm, providing a unifying view of gradient calculation techniques for recurrent networks with local feedback.
One approach to gradient information computation in RNNs with arbitrary architectures is based on signal-flow graphs diagrammatic derivation.
[90] The connectionist temporal classification (CTC)[91] is a specialized loss function for training RNNs for sequence modeling problems where the timing is variable.
Typically, the sum-squared difference between the predictions and the target values specified in the training sequence is used to represent the error of the current weight vector.
The fitness function is evaluated as follows: Many chromosomes make up the population; therefore, many different neural networks are evolved until a stopping criterion is satisfied.
The independently recurrent neural network (IndRNN)[87] addresses the gradient vanishing and exploding problems in the traditional fully connected RNN.
[96] A generative model partially overcame the vanishing gradient problem[55] of automatic differentiation or backpropagation in neural networks in 1992.
[101] Hierarchical recurrent neural networks are useful in forecasting, helping to predict disaggregated inflation components of the consumer price index (CPI).
Evaluation of a substantial dataset from the US CPI-U index demonstrates the superior performance of the HRNN model compared to various established inflation prediction methods.
[citation needed] Such a hierarchy also agrees with theories of memory posited by philosopher Henri Bergson, which have been incorporated into an MTRNN model.
[108] A continuous-time recurrent neural network (CTRNN) uses a system of ordinary differential equations to model the effects on a neuron of the incoming inputs.
, the rate of change of activation is given by: Where: CTRNNs have been applied to evolutionary robotics where they have been used to address vision,[109] co-operation,[110] and minimal cognitive behaviour.
The effect of memory-based learning for the recognition of sequences can also be implemented by a more biological-based model which uses the silencing mechanism exhibited in neurons with a relatively high frequency spiking activity.