Variational autoencoder
In machine learning, a variational autoencoder (VAE) is an artificial neural network architecture introduced by Diederik P. Kingma and Max Welling.
[1] It is part of the families of probabilistic graphical models and variational Bayesian methods.
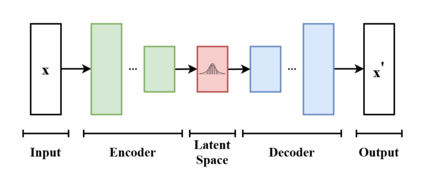
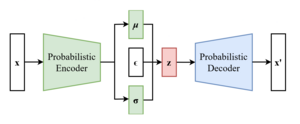
[2] In addition to being seen as an autoencoder neural network architecture, variational autoencoders can also be studied within the mathematical formulation of variational Bayesian methods, connecting a neural encoder network to its decoder through a probabilistic latent space (for example, as a multivariate Gaussian distribution) that corresponds to the parameters of a variational distribution.
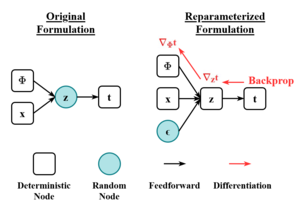
Both networks are typically trained together with the usage of the reparameterization trick, although the variance of the noise model can be learned separately.
[7] A variational autoencoder is a generative model with a prior and noise distribution respectively.
Usually such models are trained using the expectation-maximization meta-algorithm (e.g. probabilistic PCA, (spike & slab) sparse coding).
Such a scheme optimizes a lower bound of the data likelihood, which is usually computationally intractable, and in doing so requires the discovery of q-distributions, or variational posteriors.
These q-distributions are normally parameterized for each individual data point in a separate optimization process.
However, variational autoencoders use a neural network as an amortized approach to jointly optimize across data points.
In that way, the same parameters are reused for multiple data points, which can result in massive memory savings.
The first neural network takes as input the data points themselves, and outputs parameters for the variational distribution.
To optimize this model, one needs to know two terms: the "reconstruction error", and the Kullback–Leibler divergence (KL-D).
Both terms are derived from the free energy expression of the probabilistic model, and therefore differ depending on the noise distribution and the assumed prior of the data, here referred to as p-distribution.
The KL-D from the free energy expression maximizes the probability mass of the q-distribution that overlaps with the p-distribution, which unfortunately can result in mode-seeking behaviour.
The "reconstruction" term is the remainder of the free energy expression, and requires a sampling approximation to compute its expectation value.
[8] More recent approaches replace Kullback–Leibler divergence (KL-D) with various statistical distances, see see section "Statistical distance VAE variants" below.. From the point of view of probabilistic modeling, one wants to maximize the likelihood of the data
respectively, and as a member of the exponential family it is easy to work with as a noise distribution.
According to the chain rule, the equation can be rewritten as In the vanilla variational autoencoder,
It is now possible to define the set of the relationships between the input data and its latent representation as Unfortunately, the computation of
To speed up the calculus to make it feasible, it is necessary to introduce a further function to approximate the posterior distribution as with
In this way, the problem is to find a good probabilistic autoencoder, in which the conditional likelihood distribution
Like many deep learning approaches that use gradient-based optimization, VAEs require a differentiable loss function to update the network weights through backpropagation.
For variational autoencoders, the idea is to jointly optimize the generative model parameters
As reconstruction loss, mean squared error and cross entropy are often used.
That is, maximizing the log-likelihood of the observed data, and minimizing the divergence of the approximate posterior
Many variational autoencoders applications and extensions have been used to adapt the architecture to other domains and improve its performance.
-VAE is an implementation with a weighted Kullback–Leibler divergence term to automatically discover and interpret factorised latent representations.
[13][14] The conditional VAE (CVAE), inserts label information in the latent space to force a deterministic constrained representation of the learned data.
[15] Some structures directly deal with the quality of the generated samples[16][17] or implement more than one latent space to further improve the representation learning.
Some architectures mix VAE and generative adversarial networks to obtain hybrid models.