Zero-suppressed decision diagram
This data structure provides a canonically compact representation of sets, particularly suitable for certain combinatorial problems.
This provides an alternative strong normal form, with improved compression of sparse sets.
In 1993, Shin-ichi Minato from Japan modified Randal Bryant's BDDs for solving combinatorial problems.
His "Zero-Suppressed" BDDs aim to represent and manipulate sparse sets of bit vectors.
According to Bryant, it is possible to use forms of logic functions to express problems involving sum-of-products.
Such forms are often represented as sets of "cubes", each denoted by a string containing symbols 0, 1, and -.
By using ZDDs, one can reduce the size of the representation of a set of n-bit vectors in OBDDs by at most a factor of n. In practice, the optimization is statistically significant.
One feature of ZDDs is that the form does not depend on the number of input variables as long as the combination sets are the same.
It is unnecessary to fix the number of input variables before generating graphs.
It is, however, better to use the original BDDs when representing ordinary Boolean functions, as shown in Figure 7.
Random access is fast, and any operation possible for an array of sets can be done with efficiency on a ZDD.
According to Minato, the above operations for ZDDs can be executed recursively like original BDDs.
Using Getnode(), we can then represent other basic operations as follows: These algorithms take an exponential time for the number of variables in the worst case; however, we can improve the performance by using a cache that memorizes results of recent operations in a similar fashion in BDDs.
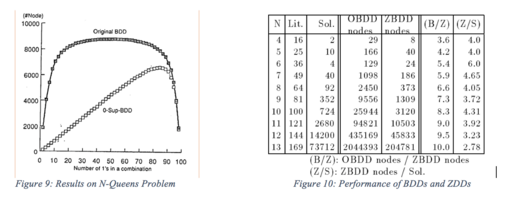
Without any duplicates, the algorithms can operate in a time that is proportional to the size of graphs, as shown in Figure 9 and 10.
Compared to binary trees, tries, or hash tables, a ZDD may not be the best to complete simple searches, yet it is efficient in retrieving data that is only partially specified, or data that is only supposed to match a key approximately.
In fact, by using a ZDD, one can represent those five letter words as a sparse function
In spite of having similar theories and algorithms, ZDDs outperform BDDs for this problem with quite a large margin.
To search words containing a certain pattern, one may use family algebra on ZDDs to compute
The absence of a LO branch leaving node 12 indicates that any path that does not go from 1 to 3 must therefore go from 1 to 2.
A real world example for simple paths was proposed by Randal Bryant, "Suppose I wanted to take a driving tour of the Continental U.S., visiting all of the state capitols, and passing through each state only once.
Figure 14 shows an undirected graph for this roadmap, the numbers indicating the shortest distances between neighboring capital cities.
The problem is to choose a subset of these edges that form a Hamiltonian path of smallest total length.
Every Hamiltonian path in this graph must either start or end at Augusta, Maine(ME).
According to Knuth, this ZDD turns out to have only 7850 nodes, and it effectively shows that exactly 437,525,772,584 simple paths from CA to ME are possible.
By number of edges, the generating function is so the longest such paths are Hamiltonian, with a size of 2,707,075.
Consider that, Although one can solve this problem by constructing OBDDs, it is more efficient to use ZDDs.
Each step can be defined as follows: The ZDD for S8 consists of all potential solutions of the 8-Queens problem.
Using cache to avoid duplicates can improve the N-Queens problems up to 4.5 times faster than using only the basic operations (as defined above), shown in Figure 10.
Olaf Schröer, M. Löbbing, and Ingo Wegener approached this problem, namely on a board, by assigning Boolean variables for each edge on the graph, with a total of 156 variables to designate all the edges.
Since this method involves unate cube set expressions, ZDDs are more efficient.