Activation function
The activation function of a node in an artificial neural network is a function that calculates the output of the node based on its individual inputs and their weights.
Nontrivial problems can be solved using only a few nodes if the activation function is nonlinear.
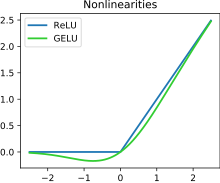
[1] Modern activation functions include the logistic (sigmoid) function used in the 2012 speech recognition model developed by Hinton et al;[2] the ReLU used in the 2012 AlexNet computer vision model[3][4] and in the 2015 ResNet model; and the smooth version of the ReLU, the GELU, which was used in the 2018 BERT model.
For instance, the strictly positive range of the softplus makes it suitable for predicting variances in variational autoencoders.
Non-saturating activation functions, such as ReLU, may be better than saturating activation functions, because they are less likely to suffer from the vanishing gradient problem.
Often used examples include:[clarification needed] In biologically inspired neural networks, the activation function is usually an abstraction representing the rate of action potential firing in the cell.
[9] In its simplest form, this function is binary—that is, either the neuron is firing or not.
Neurons also cannot fire faster than a certain rate, motivating sigmoid activation functions whose range is a finite interval.
If a line has a positive slope, on the other hand, it may reflect the increase in firing rate that occurs as input current increases.
A special class of activation functions known as radial basis functions (RBFs) are used in RBF networks.
is the vector representing the function center and
are parameters affecting the spread of the radius.
[11][12] Folding activation functions are extensively used in the pooling layers in convolutional neural networks, and in output layers of multiclass classification networks.
These activations perform aggregation over the inputs, such as taking the mean, minimum or maximum.
The following table compares the properties of several activation functions that are functions of one fold x from the previous layer or layers: where
λ , σ , μ , β
[19] The following table lists activation functions that are not functions of a single fold x from the previous layer or layers:
In quantum neural networks programmed on gate-model quantum computers, based on quantum perceptrons instead of variational quantum circuits, the non-linearity of the activation function can be implemented with no need of measuring the output of each perceptron at each layer.
The quantum properties loaded within the circuit such as superposition can be preserved by creating the Taylor series of the argument computed by the perceptron itself, with suitable quantum circuits computing the powers up to a wanted approximation degree.
Because of the flexibility of such quantum circuits, they can be designed in order to approximate any arbitrary classical activation function.