Attention (machine learning)
In natural language processing, importance is represented by "soft" weights assigned to each word in a sentence.
Earlier designs implemented the attention mechanism in a serial recurrent neural network (RNN) language translation system, but a more recent design, namely the transformer, removed the slower sequential RNN and relied more heavily on the faster parallel attention scheme.
Attention allows a token equal access to any part of a sentence directly, rather than only through the previous state.
Academic reviews of the history of the attention mechanism are provided in Niu et al.[1] and Soydaner.
[3] In 1953, Colin Cherry studied selective attention in the context of audition, known as the cocktail party effect.
[5] Selective attention of vision was studied in the 1960s by George Sperling's partial report paradigm.
It was also noticed that saccade control is modulated by cognitive processes, insofar as the eye moves preferentially towards areas of high salience.
[7][8] Meanwhile, developments in neural networks had inspired circuit models of biological visual attention.
[23] During the deep learning era, attention mechanism was developed to solve similar problems in encoding-decoding.
If the input text is long, the fixed-length vector would be unable to carry enough information for accurate decoding.
One problem with seq2seq models was their use of recurrent neural networks, which are not parallelizable as both the encoder and the decoder must process the sequence token-by-token.
Decomposable attention[28] attempted to solve this problem by processing the input sequence in parallel, before computing a "soft alignment matrix" (alignment is the terminology used by Bahdanau et al[27]) in order to allow for parallel processing.
[30] It was termed intra-attention[31] where an LSTM is augmented with a memory network as it encodes an input sequence.
This correlation is captured as neuronal weights learned during training with backpropagation.This attention scheme has been compared to the Query-Key analogy of relational databases.
Possibly because the simplistic database analogy is flawed, much effort has gone into understand Attention further by studying their roles in focused settings, such as in-context learning,[32] masked language tasks,[33] stripped down transformers,[34] bigram statistics,[35] N-gram statistics,[36] pairwise convolutions,[37] and arithmetic factoring.
Networks that perform verbatim translation without regard to word order would show the highest scores along the (dominant) diagonal of the matrix.
After the encoder has finished processing, the decoder starts operating over the hidden vectors, to produce an output sequence
This can be interpreted as saying that the attention weight should be mostly applied to the 0th hidden vector of the encoder, a little to the 1st, and essentially none to the rest.
In order to make a properly weighted sum, we need to transform this list of dot products into a probability distribution over
, the model would be forced to use the same hidden vector for both key and value, which might not be appropriate, as these two tasks are not the same.This is the dot-attention mechanism.
In fact, it is theoretically possible for query, key, and value vectors to all be different, though that is rarely done in practice.
[46][47] Much effort has gone into understand Attention further by studying their roles in focused settings, such as in-context learning,[32] masked language tasks,[33] stripped down transformers,[34] bigram statistics,[35] N-gram statistics,[36] pairwise convolutions,[37] and arithmetic factoring.
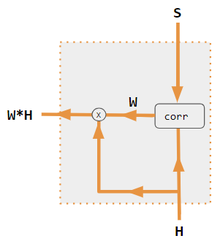
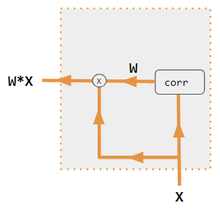
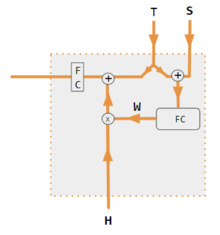
In the figures below, W is the matrix of context attention weights, similar to the formula in Core Calculations section above.
Therefore, when the input is long, calculating the attention matrix requires a lot of GPU memory.
Flash attention is an implementation that reduces the memory needs and increases efficiency without sacrificing accuracy.
It achieves this by partitioning the attention computation into smaller blocks that fit into the GPU's faster on-chip memory, reducing the need to store large intermediate matrices and thus lowering memory usage while increasing computational efficiency.
These properties are inherited when applying linear transforms to the inputs and outputs of QKV attention blocks.
For example, a simple self-attention function defined as: is permutation equivariant with respect to re-ordering the rows of the input matrix
When QKV attention is used as a building block for an autoregressive decoder, and when at training time all input and output matrices have
The permutation invariance and equivariance properties of standard QKV attention do not hold for the masked variant.