Scoring rule
In decision theory, a scoring rule[1] provides evaluation metrics for probabilistic predictions or forecasts.
Scoring rules answer the question "how good is a predicted probability distribution compared to an observation?"
Although this might differ for individual observations, this should result in a minimization of the expected score if the "correct" distributions are predicted.
A common interpretation of probabilistic models is that they aim to quantify their own predictive uncertainty.
Although the example given concerns the probabilistic forecasting of a real valued target variable, a variety of different scoring rules have been designed with different target variables in mind.
are negatively (positively) oriented if smaller (larger) values mean better.
Many probabilistic forecasting models are training via the sample average score, in which a set of predicted distributions
Strictly proper scoring rules and strictly consistent scoring functions encourage honest forecasts by maximization of the expected reward: If a forecaster is given a reward of
), then the highest expected reward (lowest score) is obtained by reporting the true probability distribution.
If the actual percentage was substantially different from the stated probability we say that the forecaster is poorly calibrated.
A bonus system designed around a proper scoring rule will incentivize the forecaster to report probabilities equal to his personal beliefs.
One way to use this rule would be as a cost based on the probability that a forecaster or algorithm assigns, then checking to see which event actually occurs.
An important difference between these two rules is that a forecaster should strive to maximize the quadratic score
This scoring rule can be used to computationally simplify parameter inference and address Bayesian model comparison with arbitrarily-vague priors.
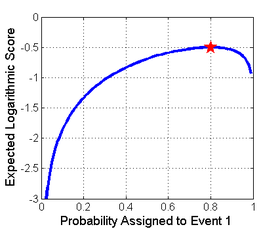
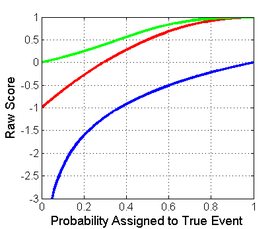
Shown below on the left is a graphical comparison of the Logarithmic, Quadratic, and Spherical scoring rules for a binary classification problem.
The magnitude differences are not relevant however as scores remain proper under affine transformation.
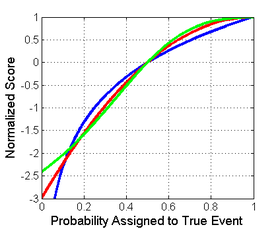
A reasonable choice of normalization is shown at the picture on the right where all scores intersect the points (0.5,0) and (1,1).
The logarithmic score for continuous variables has strong ties to Maximum likelihood estimation.
For distributions with finite first moment, the continuous ranked probability score can be written as:[1] where
:[12] For many popular families of distributions, closed-form expressions for the continuous ranked probability score have been derived.
[13][14] CRPS was also adapted to survival analysis to cover censored events.
denotes the probability density function of the predicted multivariate distribution
It has been suggested that the energy score is somewhat ineffective when evaluating the intervariable dependency structure of the forecasted multivariate distribution.
is ill-defined (i.e. its conditional event has zero likelihood), CRPS scores over this distribution are defined as infinite.
All proper scoring rules are equal to weighted sums (integral with a non-negative weighting functional) of the losses in a set of simple two-alternative decision problems that use the probabilistic prediction, each such decision problem having a particular combination of associated cost parameters for false positive and false negative decisions.
A strictly proper scoring rule corresponds to having a nonzero weighting for all possible decision thresholds.
All binary scores are local because the probability assigned to the event that did not occur is determined so there is no degree of flexibility to vary over.
can be decomposed into the sum of three components, called uncertainty, reliability, and resolution,[25][26] which characterize different attributes of probabilistic forecasts: If a score is proper and negatively oriented (such as the Brier Score), all three terms are positive definite.
The uncertainty component is equal to the expected score of the forecast which constantly predicts the average event frequency.
The reliability component penalizes poorly calibrated forecasts, in which the predicted probabilities do not coincide with the event frequencies.