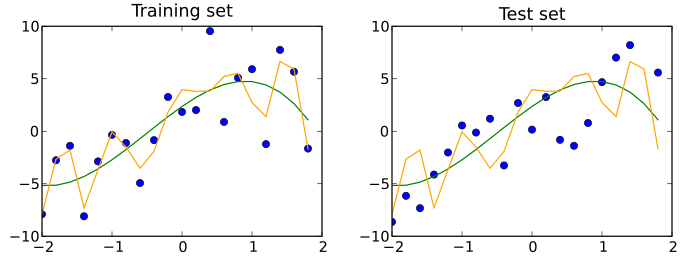
Training, validation, and test data sets
[1] Such algorithms function by making data-driven predictions or decisions,[2] through building a mathematical model from input data.
[4] The model (e.g. a naive Bayes classifier) is trained on the training data set using a supervised learning method, for example using optimization methods such as gradient descent or stochastic gradient descent.
Based on the result of the comparison and the specific learning algorithm being used, the parameters of the model are adjusted.
[3] The validation data set provides an unbiased evaluation of a model fit on the training data set while tuning the model's hyperparameters[5] (e.g. the number of hidden units—layers and layer widths—in a neural network[4]).
[6] This simple procedure is complicated in practice by the fact that the validation data set's error may fluctuate during training, producing multiple local minima.
[5] To reduce the risk of issues such as over-fitting, the examples in the validation and test data sets should not be used to train the model.
[13] An example of a hyperparameter for artificial neural networks includes the number of hidden units in each layer.
Since this procedure can itself lead to some overfitting to the validation set, the performance of the selected network should be confirmed by measuring its performance on a third independent set of data called a test set.An application of this process is in early stopping, where the candidate models are successive iterations of the same network, and training stops when the error on the validation set grows, choosing the previous model (the one with minimum error).
Those predictions are compared to the examples' true classifications to assess the model's accuracy.
[12] However, when using a method such as cross-validation, two partitions can be sufficient and effective since results are averaged after repeated rounds of model training and testing to help reduce bias and variability.
This is the most blatant example of the terminological confusion that pervades artificial intelligence research.
To confirm the model's performance, an additional test data set held out from cross-validation is normally used.
[17] Types of such omissions include:[17] An example of an omission of particular circumstances is a case where a boy was able to unlock the phone because his mother registered her face under indoor, nighttime lighting, a condition which was not appropriately included in the training of the system.