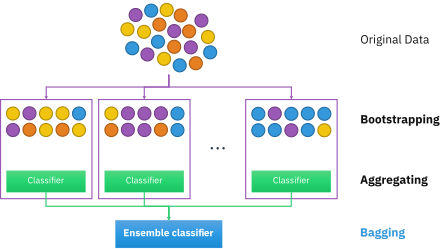
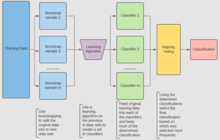
Bootstrap aggregating
models are fitted using the above bootstrap samples and combined by averaging the output (for regression) or voting (for classification).
[4][5] On the other hand, it can mildly degrade the performance of stable methods such as k-nearest neighbors.
Their names are Emily, Jessie, George, Constantine, Lexi, Theodore, John, James, Rachel, Anthony, Ellie, and Jamal.
In this case, the remaining samples who were not selected are Emily, Jessie, George, Rachel, and Jamal.
Creating the bootstrap and out-of-bag datasets is crucial since it is used to test the accuracy of a random forest algorithm.
The next step of the algorithm involves the generation of decision trees from the bootstrapped dataset.
To achieve this, the process examines each gene/feature and determines for how many samples the feature's presence or absence yields a positive or negative result.
The diagram below shows a decision tree of depth two being used to classify data.
This process is repeated recursively for successive levels of the tree until the desired depth is reached.
The next part of the algorithm involves introducing yet another element of variability amongst the bootstrapped trees.
In addition to each tree only examining a bootstrapped set of samples, only a small but consistent number of unique features are considered when ranking them as classifiers.
Consequently, the trees are more likely to return a wider array of answers, derived from more diverse knowledge.
In a random forest, each tree "votes" on whether or not to classify a sample as positive based on its features.
An example of this is given in the diagram below, where the four trees in a random forest vote on whether or not a patient with mutations A, B, F, and G has cancer.
[6] They are primarily useful for classification as opposed to regression, which attempts to draw observed connections between statistical variables in a dataset.
This makes random forests particularly useful in such fields as banking, healthcare, the stock market, and e-commerce where it is important to be able to predict future results based on past data.
If the trees in the random forests are too deep, overfitting can still occur due to over-specificity.
[citation needed] As an integral component of random forests, bootstrap aggregating is very important to classification algorithms, and provides a critical element of variability that allows for increased accuracy when analyzing new data, as discussed below.
The following are key steps in creating an efficient random forest: For classification, use a training set
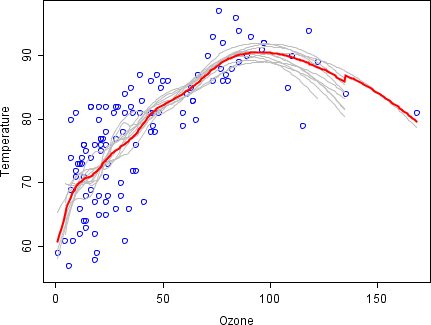
The relationship between temperature and ozone appears to be nonlinear in this dataset, based on the scatter plot.
Rather than building a single smoother for the complete dataset, 100 bootstrap samples were drawn.
Each sample is composed of a random subset of the original data and maintains a semblance of the master set's distribution and variability.
By taking the average of 100 smoothers, each corresponding to a subset of the original dataset, we arrive at one bagged predictor (red line).
The red line's flow is stable and does not overly conform to any data point(s).
He argued, "If perturbing the learning set can cause significant changes in the predictor constructed, then bagging can improve accuracy".