Jaccard index
The Jaccard index is a statistic used for gauging the similarity and diversity of sample sets.
It was developed by Grove Karl Gilbert in 1884 as his ratio of verification (v)[1] and now is often called the critical success index in meteorology.
[2] It was later developed independently by Paul Jaccard, originally giving the French name coefficient de communauté (community coefficient),[3][4] and independently formulated again by T. Tanimoto.
The Jaccard index measures similarity between finite non-empty sample sets and is defined as the size of the intersection divided by the size of the union of the sample sets: Note that by design,
Both the exact solution and approximation methods are available for hypothesis testing with the Jaccard index.
Jaccard distance is commonly used to calculate an n × n matrix for clustering and multidimensional scaling of n sample sets.
The MinHash min-wise independent permutations locality sensitive hashing scheme may be used to efficiently compute an accurate estimate of the Jaccard similarity index of pairs of sets, where each set is represented by a constant-sized signature derived from the minimum values of a hash function.
[6] When used for binary attributes, the Jaccard index is very similar to the simple matching coefficient.
In market basket analysis, for example, the basket of two consumers who we wish to compare might only contain a small fraction of all the available products in the store, so the SMC will usually return very high values of similarities even when the baskets bear very little resemblance, thus making the Jaccard index a more appropriate measure of similarity in that context.
In other contexts, where 0 and 1 carry equivalent information (symmetry), the SMC is a better measure of similarity.
For example, vectors of demographic variables stored in dummy variables, such as gender, would be better compared with the SMC than with the Jaccard index since the impact of gender on similarity should be equal, independently of whether male is defined as a 0 and female as a 1 or the other way around.
However, when we have symmetric dummy variables, one could replicate the behaviour of the SMC by splitting the dummies into two binary attributes (in this case, male and female), thus transforming them into asymmetric attributes, allowing the use of the Jaccard index without introducing any bias.
The SMC remains, however, more computationally efficient in the case of symmetric dummy variables since it does not require adding extra dimensions.
The weighted Jaccard similarity described above generalizes the Jaccard Index to positive vectors, where a set corresponds to a binary vector given by the indicator function, i.e.
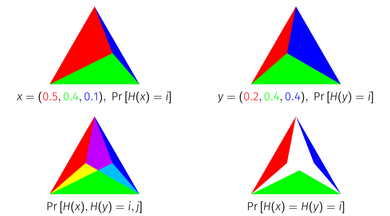
The Probability Jaccard Index has a geometric interpretation as the area of an intersection of simplices.
If you overlay two distributions represented in this way on top of each other, and intersect the simplices corresponding to each item, the area that remains is equal to the Probability Jaccard Index of the distributions.
Consider the problem of constructing random variables such that they collide with each other as much as possible.
In a fairly strong sense described below, the Probability Jaccard Index is an optimal way to align these random variables.
(The theorem uses the word "sampling method" to describe a joint distribution over all distributions on a space, because it derives from the use of weighted minhashing algorithms that achieve this as their collision probability.)
This theorem has a visual proof on three element distributions using the simplex representation.
Many sources[12] cite an IBM Technical Report[5] as the seminal reference.
In "A Computer Program for Classifying Plants", published in October 1960,[13] a method of classification based on a similarity ratio, and a derived distance function, is given.
In that paper, a "similarity ratio" is given over bitmaps, where each bit of a fixed-size array represents the presence or absence of a characteristic in the plant being modelled.
[citation needed] Tanimoto goes on to define a "distance" based on this ratio, defined for bitmaps with non-zero similarity: This coefficient is, deliberately, not a distance metric.
[clarification needed][citation needed] If Jaccard or Tanimoto similarity is expressed over a bit vector, then it can be written as where the same calculation is expressed in terms of vector scalar product and magnitude.
This representation relies on the fact that, for a bit vector (where the value of each dimension is either 0 or 1) then and This is a potentially confusing representation, because the function as expressed over vectors is more general, unless its domain is explicitly restricted.
is in fact a distance metric over vectors or multisets in general, whereas its use in similarity search or clustering algorithms may fail to produce correct results.
It is, however, made clear within the paper that the context is restricted by the use of a (positive) weighting vector
Under these circumstances, the function is a proper distance metric, and so a set of vectors governed by such a weighting vector forms a metric space under this function.
In confusion matrices employed for binary classification, the Jaccard index can be framed in the following formula: where TP are the true positives, FP the false positives and FN the false negatives.