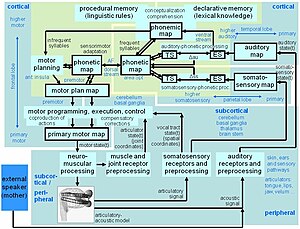
Neurocomputational speech processing
In the ACT model (see below), it is assumed that an auditory state can be represented by a "neural spectrogram" (see Fig.
The neural representations occurring in the sensory and motor maps (as introduced above) are distributed representations (Hinton et al. 1968[5]): Each neuron within the sensory or motor map is more or less activated, leading to a specific activation pattern.
The speech sound map - assumed to be located in the inferior and posterior portion of Broca's area (left frontal operculum) - represents (phonologically specified) language-specific speech units (sounds, syllables, words, short phrases).
The activated neural representation on the level of that motor map determines the articulation of a speech unit, i.e. controls all articulators (lips, tongue, velum, glottis) during the time interval for producing that speech unit.
Forward control also involves subcortical structures like the cerebellum, not modelled in detail here.
This phonetic variability is the motivation to define sensory target regions in the DIVA model (see Guenther et al.
If the current sensory state deviates from the intended sensory state, both error maps are generating feedback commands which are projected towards the motor map and which are capable to correct the motor activation pattern and subsequently the articulation of a speech unit under production.
Two important phases of early speech acquisition are modeled in the DIVA approach: Learning by babbling and by imitation.
This training is done by generating an amount of semi-random feedforward commands, i.e. the DIVA model "babbles".
At this point the DIVA model has available the sensory and associated motor activation pattern for different speech items, which enables the model to tune the synaptic projections between sensory error maps and motor map.
Thus the DIVA model tries to "imitate" an auditory speech item by attempting to find a proper feedforward motor command.
Then the model updates the current feedforward motor command by the current feedback motor command generated from the auditory error map of the auditory feedback system.
During imitation the DIVA model is also capable of tuning the synaptic projections from speech sound map to somatosensory target region map, since each new imitation attempt produces a new articulation of the speech item and thus produces a somatosensory state pattern which is associated with the phonemic representation of that speech item.
The motor plan or vocal tract action score comprises temporally overlapping vocal tract actions, which are programmed and subsequently executed by the motor programming, execution, and control module.
This module gets real-time somatosensory feedback information for controlling the correct execution of the (intended) motor plan.
The Birkholz 3D articulatory synthesizer is used in order to generate the acoustic speech signal.
At the level of the sensory-phonetic processing modules, auditory and somatosensory information is stored in short-term memory and the external sensory signal (ES, Fig.
The hypothetical cortical location of neural maps within the ACT model is shown in Fig.
This neural pathway between the two locations of the phonetic map is assumed to be a part of the fasciculus arcuatus (AF, see Fig.
The ventral path of speech perception (see Hickok and Poeppel 2007[18]) would directly activate a lexical item, but is not implemented in ACT.
Rather, in ACT the activation of a phonemic state occurs via the phonemic map and thus may lead to a coactivation of motor representations for that speech item (i.e. dorsal pathway of speech perception; ibid.).
In our neurocomputational model ACT a motor plan is quantified as a vocal tract action score.
Vocal tract action scores quantitatively determine the number of vocal tract actions (also called articulatory gestures), which need to be activated in order to produce a speech item, their degree of realization and duration, and the temporal organization of all vocal tract actions building up a speech item (for a detailed description of vocal tract actions scores see e.g. Kröger & Birkholz 2007).
[19] The detailed realization of each vocal tract action (articulatory gesture) depends on the temporal organization of all vocal tract actions building up a speech item and especially on their temporal overlap.
Thus the detailed realization of each vocal tract action within a speech item is specified below the motor plan level in our neurocomputational model ACT (see Kröger et al.
A possible solution of this problem could be a direct coupling of action repository and mental lexicon without explicitly introducing a phonemic map at the beginning of speech acquisition (even at the beginning of imitation training; see Kröger et al. 2011 PALADYN Journal of Behavioral Robotics).
A very important issue for all neuroscientific or neurocomputational approaches is to separate structure and knowledge.
Different learning experiments were carried out with the model ACT in order to learn (i) a five-vowel system /i, e, a, o, u/ (see Kröger et al. 2009), (ii) a small consonant system (voiced plosives /b, d, g/ in combination with all five vowels acquired earlier as CV syllables (ibid.
), (iii) a small model language comprising the five-vowel system, voiced and unvoiced plosives /b, d, g, p, t, k/, nasals /m, n/ and the lateral /l/ and three syllable types (V, CV, and CCV) (see Kröger et al. 2011)[21] and (iv) the 200 most frequent syllables of Standard German for a 6-year-old child (see Kröger et al.
Furthermore, the model ACT was able to exhibit the McGurk effect, if a specific mechanism of inhibition of neurons of the level of the phonetic map was implemented (see Kröger and Kannampuzha 2008).