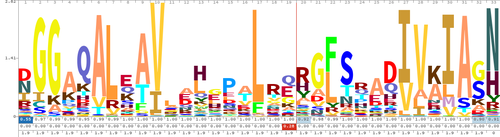
Sequence logo
Sequence logos are frequently used to depict sequence characteristics such as protein-binding sites in DNA or functional units in proteins.
A sequence logo consists of a stack of letters at each position.
The relative sizes of the letters indicate their frequency in the sequences.
The total height of the letters depicts the information content of the position, in bits.
To create sequence logos, related DNA, RNA or protein sequences, or DNA sequences that have common conserved binding sites, are aligned so that the most conserved parts create good alignments.
The sequence logo will show how well residues are conserved at each position: the higher the number of residues, the higher the letters will be, because the better the conservation is at that position.
The height of the entire stack of residues is the information measured in bits.
is the uncertainty (sometimes called the Shannon entropy) of position
is the relative frequency of base or amino acid
The main, and obvious, advantage of consensus logos over sequence logos is their ability to be embedded as text in any Rich Text Format supporting editor/viewer and, therefore, in scientific manuscripts.
As a result, compared to a sequence logo, the consensus logo omits information (the relative contribution of each character to the conservation of that position in the motif/alignment).
That being said, the need to include graphic figures in order to display sequence logos has perpetuated the use of consensus sequences in scientific manuscripts, even though they fail to convey information on both conservation and frequency.
In an HMM sequence logo used by Pfam, three rows are added to indicate the frequencies of occupancy (presence) and insertion, as well as the expected insertion length.