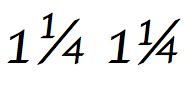Universal Character Set characters
UCS, official designation: ISO/IEC 10646), is an international standard to map characters, discrete symbols used in natural language, mathematics, music, and other domains, to unique machine-readable data values.
By creating this mapping, the UCS enables computer software vendors to interoperate, and transmit—interchange—UCS-encoded text strings from one to another.
As of Unicode 16.0, released in September 2024, 299,056 (27%) of these code points are allocated, 155,063 (14%) have been assigned characters, 137,468 (12%) are reserved for private use, 2,048 are used to enable the mechanism of surrogates, and 66 are designated as noncharacters, leaving the remaining 815,056 (73%) unallocated.
In addition to the UCS, the supplementary Unicode Standard, (not a joint project with ISO, but rather a publication of the Unicode Consortium,) provides other implementation details such as: Computer software end users enter these characters into programs through various input methods, for example, physical keyboards or virtual character palettes.
The entity must either be predefined (built into the markup language) or explicitly declared in a Document Type Definition (DTD).
Unicode and ISO divide the set of code points into 17 planes, each capable of containing 65536 distinct characters or 1,114,112 total.
The first 256 code points in the UCS correspond with those of ISO 8859-1, the most popular 8-bit character encoding in the Western world.
The general categories are: letter, mark, number, punctuation, symbol, or control (in other words a formatting or non-graphical character).
Because the more complex font formats, such as OpenType or Apple Advanced Typography, provide for contextual substitution and positioning of glyphs, a simple text layout engine might rely entirely on the font for all decisions of glyph choice and placement.
In the same situation a more complex engine may combine information from the font with its own rules to achieve its own idea of best rendering.
Unicode 5.1 introduces the Mathematical Invisible Plus character as well (U+2064) which may indicate that an integral number followed by a fraction should denote their sum, but not their product.
Simple text layout engines tend not to synthesize fractions at all, and instead draw the glyphs as a linear sequence as described in the Unicode fallback scheme.
More sophisticated layout engines face two practical choices: they can follow Unicode's recommendation, or they can rely on the font's own instructions for synthesizing fractions.
Most fonts of complex formats can instruct the layout engine to replace a plain text sequence such as 1⁄2 with the precomposed ½ glyph.
While Unicode is designed to handle multiple languages, multiple writing systems and even text that flows either left-to-right or right-to-left with minimal author intervention, there are special circumstances where the mix of bidirectional text can become intricate—requiring more author control.
The grapheme LATIN CAPITAL A WITH DIAERESIS Ä is an example where a character can be represented by more than one code point.
Finally, the Word Joiner (U+2060) inhibits line breaks and also involves none of the white space produced by a baseline advance.
While these spaces of varying width are important in typography, the Unicode processing model calls for such visual effects to be handled by rich text, markup and other such protocols.
They are included in the Unicode repertoire primarily to handle lossless roundtrip transcoding from other character set encodings.
In this context this means that they effectively add no semantic content to the text, but instead provide styling control.
This includes private-use characters, which though not formally designated by the Unicode standard for a particular purpose, require a sender and recipient to have agreed in advance how they should be interpreted for meaningful information interchange to take place.
[9] In public systems their use is more problematic, since there is no registry and no way to prevent several organizations from adopting the same code points for different purposes.
These systems had private use areas to encode what the Japanese call gaiji (rare characters not normally found in fonts) in application-specific ways.
The UCS uses surrogates to address characters outside the initial Basic Multilingual Plane without resorting to more-than-16-bit-word representations.
In the Python programming language, individual surrogate codes are used to embed undecodable bytes in Unicode strings.
Corrigendum #9 of the standard later stated that this was leading to "inappropriate over-rejection", clarifying that "[Noncharacters] are not illegal in interchange nor do they cause ill-formed Unicode text", and removing the original claim.
In addition, Unicode approaches diacritic modified letters as separate characters that, when rendered, become a single glyph.
This has the potential to significantly reduce the number of active code points needed for the character set.
As an example, consider a language that uses the Latin script and combines the diaeresis with the upper- and lower-case letters "a", "o", and "u".
However, for UCS and Unicode in particular, the preferred approach is to always encode or map that letter to the same character no matter where it appears in a word.