Interval estimation
Confidence intervals are used to estimate the parameter of interest from a sampled data set, commonly the mean or standard deviation.
There are multiple methods used to build a confidence interval, the correct choice depends on the data being analyzed.
For a normal distribution with a known variance, one uses the z-table to create an interval where a confidence level of 100γ% can be obtained centered around the sample mean from a data set of n measurements, .
[3] If the underlying distribution is unknown, one can utilize bootstrapping to create bounds about the median of the data set.
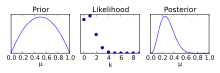
Utilizing the likelihood-based method, confidence intervals can be found for exponential, Weibull, and lognormal means.
Additionally, likelihood-based approaches can give confidence intervals for the standard deviation.
It is also possible to create a prediction interval by combining the likelihood function and the future random variable.
The founder, R.A. Fisher, who had been developing inverse probability methods, had his own questions about the validity of the process.
While fiducial inference was developed in the early twentieth century, the late twentieth century believed that the method was inferior to the frequentist and Bayesian approaches but held an important place in historical context for statistical inference.
[8] Fuzzy logic is used to handle decision-making in a non-binary fashion for artificial intelligence, medical decisions, and other fields.
In general, it takes inputs, maps them through fuzzy inference systems, and produces an output decision.
When looking at fuzzy logic rule evaluation, membership functions convert our non-binary input information into tangible variables.
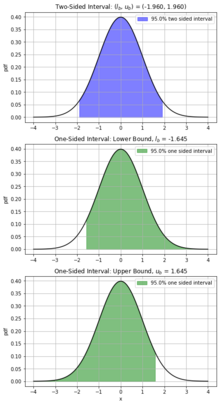
Two-sided intervals estimate a parameter of interest, Θ, with a level of confidence, γ, using a lower (
Examples may include estimating the average height of males in a geographic region or lengths of a particular desk made by a manufacturer.
Typically, a one-sided interval is required when the estimate's minimum or maximum bound is not of interest.
When determining the statistical significance of a parameter, it is best to understand the data and its collection methods.
[9] After experimenting, a typical first step in creating interval estimates is exploratory analysis plotting using various graphical methods.
Producing interval boundaries with incorrect assumptions based on distribution makes a prediction faulty.
[10] When interval estimates are reported, they should have a commonly held interpretation within and beyond the scientific community.
In commonly occurring situations there should be sets of standard procedures that can be used, subject to the checking and validity of any required assumptions.
[11] In decision theory, which is a common approach to and justification for Bayesian statistics, interval estimation is not of direct interest.
The outcome is a decision, not an interval estimate, and thus Bayesian decision theorists use a Bayes action: they minimize expected loss of a loss function with respect to the entire posterior distribution, not a specific interval.
Katz (1975) proposes various challenges and benefits for utilizing interval estimates in legal proceedings.